
ארכיב עבור 'מה אומרת הסטטיסטיקה'
שגעון הפווארבול
שגעון הפאוורבול בארצות הברית הגיע השבוע לשיאים חדשים, לאחר שבהגרלות שנערכו ב-20.10.2018 איש לא ניחש נכונה את המספרים שעלו בגורל. הפרס הגדול, נכון לעכשיו, הוא 2.22 מיליארד דולר. אני בטוח שאתם רוצים לזכות בפרס הזה. אני רוצה לזכות בפרס הזה.
מה הסיכויים לזכות בפרס הגדול בפווארבול?
למעשה מדובר בשתי הגרלות שונות. בהגרלת המגה-מיליון הפרס הגדול הוא 1.6 מיליארד דולר, וההסתברות לזכייה בו היא בערך 1 ל-302 מיליון. בהגרלה השנייה, היא הגרלת הפווארבול, הפרס הגדול הוא "רק" 620 מיליון דולר, וההסתברות לזכייה בו היא קצת יותר גבוהה – 1 ל-292 מיליון.
כדי לזכות ב-2.2 מיליארד דולר, צריך לזכות בפרס הגדול של שתי ההגרלות, שהינן כמובן בלתי תלויות זו בזו. הסיכוי לכך הוא מכפלת הסיכויים לזכייה בשתי ההגרלות בנפרד, והוא בערך שווה ל-1 ל-88000000000000000.
צריך לזכור כי למרות שההסתברות לזכייה בפרס הגדול, בייחוד אם קונים רק כרטיס אחד, היא נמוכה מאוד, היא עדיין חיובית, כלומר יש סיכוי לזכות. מי שלא קנה כרטיס, לא יוכל לזכות. לכן, הצעד הראשון בדרך לזכייה הוא לקנות כרטיס.
האם קניית כרטיס הגרלה היא השקעה טובה?
זה תלוי כמובן בשאלה איך מגדירים האם השקעה היא טובה. אפשרות אחת היא להעריך את ההחזר הצפוי על ההשקעה. בואו לא נהיה חמדניים, ונתרכז רק בהגרלת המגה-מיליון ובפרס של 1.6 מיליארד דולר. מחיר כל כרטיס הוא שני דולר. בממוצע, מי שקונה כרטיס זוכה ב-1.6 מיליארד דולר בהסתברות של 1 ל-302 מיליון, או מפסיד 2 דולר בהסתברות כמעט קרובה ל-1. לכן ההחזר הממוצע על הכרטיס הוא בערך 1.6 מיליארד כפול 1 חלקי 302 מיליון פחות 2. זה יוצא בערך 3.30 דולר. למעשה חישבתי כאן את תוחלת הזכייה של כרטיס הגרלה. שימו לב כי התוחלת חיובית. בממוצע, מפעל ההגרלות מפסיד בהגרלה הזו 3.30 דולר על כל כרטיס שנמכר. בדרך כלל, במשחקי הימורים תוחלת הזכייה היא שלילית. למשל, אם אתם מהמרים ברולטה על ניחוש שחור/אדום, תוחלת הזכייה שלכם על כל דולר הימור היא בערך מינוס 5.2 סנט, כלומר בממוצע אתם מפסידים 5.2 סנט בכל פעם שאתם מהמרים על דולר. זה מספיק לקזינו כדי להרוויח מיליונים.
ראיתי במספר פורומים (בדיונים על הגרלות אחרות עם פרסים גדולים במיוחד) אנשים שטענו כי תוחלת הזכייה חיובית ולכן כדאי לקנות כרטיס השתתפות בהגרלה. למרבה הצער הטענה הזו לא נכונה. אותם 3.30 דולר שחישבתי למעלה הם תוחלת של כסף, ותוחלת של כסף זה לא כסף. אתם לא יכולים לקחת כרטיס להגרלה שתיערך מחרתיים ולשלם איתו במכולת, גם אם תוחלת הזכייה חיובית (( נסו ותיווכחו )). מה שיקרה זה שמועד ההגרלה יגיע, ואז תזכו, או שאולי לא. כמובן, אם תוכלו להשתתף בהגרלות כאלה כמה פעמים שתרצו, משתלם לגמרי לקנות כרטיס ועוד כרטיס ועוד כרטיס. חוק המספרים הגדולים יהיה לצידכם. אבל זה לא יקרה כמובן. ההזדמנות להשתתף בהגרלה היא חד פעמית
אבל הסיכוי לזכות כל כך קטן – ברור שאין זוכה
אמנם הסיכוי שאתם תזכו בהגרלה הוא מאוד נמוך, אך הסיכוי שמישהו יזכה בפרס הגדול הוא גבוה למדי. (( זו למעשה בעיית ימי ההולדת )). הנה הסבר אינטואיטיבי. תחשבו על קובייה. אם תטילו אותה הסיכוי שתוצאת ההטלה תהיה 6 היא 1 ל-6. אם שני אנשים יטילו כל אחד קובייה, הסיכוי שלפחות באחת ההטלות התוצאה תהיה 6 הוא גבוה יותר – בערך 1 ל-3.3. אם שלושה אנשים יטילו כל אחד קובייה, הסיכוי שלפחות באחת ההטלות התוצאה תהיה 6 הוא אפילו גבוה יותר – בערך 1 ל-2.37. וכן הלאה. אפשר לחשוב על כרטיס הגרלה כמין קובייה מטאפורית, כזו שהסיכוי לתוצאת 6 אם תטילו אותה הוא 1 ל-302 מיליון. אם יותר אנשים יטילו יותר קוביות, כלומר אם יותר כרטיסי הגרלה יימכרו, הסיכוי שתתקבל תוצאת 6, כלומר שמישהו יזכה בפרס, הולך וגדל.
כמה כרטיסים צריכים להימכר כדי שהסיכוי שלפחות כרטיס אחד יזכה יהיה 5%? 10%? 50%? מה הסיכוי ששני זוכים יחלקו את הפרס הגדול? אם אתם יודעים את מספר הכרטיסים שנמכרו, אתם יכולים לחשב את הסיכויים האלה בעזרת התפלגות פואסון. אדלג ברשותכם על הפרטים הטכניים. אפשר גם לעשות חישוב הפוך, ולחשב כמה כרטיסים צריכים להימכר כדי שההסתברות שמישהו יזכה בפרס הגדול תהיה שווה ל-50%. המספר הזה הוא בערך 210 מיליון. זה לא מספר מופרך. לפי הדיווח הזה, כ-226 מיליון כרטיסים צפויים להימכר לקראת ההגרלה הקרובה.
מה אם קונים את כל הכרטיסים?
הנה עוד רעיון שבוודאי עבר במוחו של מישהו: יש 302 מיליון צירופי מספרים אפשריים. אם נקנה 302 מיליון כרטיסים, ובכל כרטיס יופיע צירוף מספרים אחר, אז הכרטיס הזוכה חייב להיות בין הכרטיסים שקנינו. כל כרטיס עולה שני דולר, אז 302 מיליון כרטיסים יעלו 604 מיליון דולר. הפרס הגדול הוא 1600 מיליון דולר, ולכן מובטח רווח של כמעט מיליארד דולר. האם אפשר לעשות את זה?
התשובה הקצרה היא "כן". התשובה הארוכה היא "כנראה שלא".
מבחינה חוקית זה אפשרי, וזה כבר נעשה לפחות פעם אחת. בשנת 1992 הפרס הגדול בהגרלת הלוטו של מדינת וירג'יניה היה 27 מיליון דולר, והסיכוי לזכייה היה בערך 1 ל-7 מיליון. כל מה שצריך היה לעשות זה לקנות 7 מיליון כרטיסים ב-7 מיליון דולר ולגרוף רווח של 20 מיליון דולר. קבוצה של כ-2500 משקיעים התארגנה לגייס את הכסף ולרכוש את הכרטיסים. למרבה צערם הם הספיקו לקנות רק כ-5 מיליון כרטיסים עד מועד ההגרלה. לאחר קצת כסיסת ציפורניים התברר שהם אכן הצליחו לרכוש את הכרטיס הזוכה, מדינת וירג'יניה ניסתה להערים קשיים משפטיים כדי להימנע מתשלום, אך בסופו של דבר סכום הפרס הגדול שולם (וגם עוד כמה עשרות אלפי פרסים יותר קטנים). ((לפרטים נוספים ראו את ספרו של דייויד הנד The improbability Principle ))
בהגרלת המגה מיליון זה סיפור בסדר גודל אחר לגמרי. קודם כל, כדי לקנות 302 מיליון כרטיסים צריך 604 מיליון דולר, במזומן. שנית, יש לכם רק ארבעה ימים עד ההגרלה הבאה. בארבעה ימים יש 345600 שניות, כלומר תצטרכו לקנות כמעט 900 כרטיסים בכל שניה. וכמובן, אתם צריכים לוודא איכשהו שקניתם 302 מיליון כרטיסים שונים.
נניח שעשיתם את כל זה וזכיתם. הפרס משולם לזוכה ב-30 תשלומים שנתיים. מי שרוצה כסף עכשיו ומייד, יקבל רק 57% מהסכום. צריך גם לשלם מס בסך 25%. מ-1.6 מיליארדי הדולרים יישארו רק 684 מיליון. עדיין רווח נקי של 80 מיליון דולר תוך ארבעה ימים. לא רע.
אבל… כל זאת, כמובן, אם לא יהיה זוכה נוסף בפרס הגדול.
וההסתברות שיהיה זוכה נוסף או אפילו יותר אינה זניחה. כבר ראינו כי אם נמכרים עוד כ-200 מיליון כרטיסים מלבד 302 מיליון הכרטיסים שלכם, ההסתברות כי יהיה זוכה אחד נוסף לפחות היא כ-50%. אם יהיה זוכה אחד נוסף, החלק שלכם בפרס יהיה רק 800 מיליון דולר, שלאחר ההיוון ותשלום המס יתכווצו ל- 342 מיליון, וזה כבר הפסד נקי של 262 מיליון דולר. אם הפרס יתחלק בין שלושה זוכים ההפסד יהיה גבוה יותר. לא טוב. אם היו לכם 604 מיליון דולר, האם הייתם מוכנים לקחת את הסיכון?
האם כדאי לקנות כרטיס?
אני חושב שכן. אם הייתי תושב ארצות הברית הייתי קונה כרטיס. אחד. זה שעשוע נחמד ויש סיכוי כלשהו לזכות. היכן עוד תוכלו לקנות תקווה תמורת שני דולר בלבד? (( פראפרזה על דברים שאמרו פרופ' צבי גילולה ופרופ' ישראל אומן))
נשלח: 22 באוקטובר, 2018. נושאים: הימורים, מה אומרת הסטטיסטיקה.
תגובות: אין
| טראקבק
ניתוח השפעה של אירוע על נתונים לאורך זמן – Interrupted Time Series
בפוסט קודם ניתחתי מה קרה לשיעורי תאונות הדרכים בישראל בתקופת כהונתו של ישראל כץ כשר התחבורה.
כדי לענות על שאלות גון אלה – מה קורה לתופעה כזו או אחרת לאורך זמן – מומלץ להשתמש בשיטות סטטיסטיות לניתוח סדרות עיתיות (Time Series). סדרה עיתית היא סדרה של נתונים שנאספים לאורך זמן: שבועות, חודשים ואפילו שנים. ניתן גם לבדוק את השפעתו של שינוי מסויים שחל במהלך הזמן (המהווה הפרעה למגמת הסדרה), כמו שינוי קיצוני במזג האוויר, כניסת מתחרה חדש לשוק, או מינוי של שר, בעזרת טכניקה הנקראת "ניתוח סדרות עיתיות מופרעות", או באנגלית Interrupted Time Series או פשוט ITS.
ברשימה זו אסביר את הרעיונות המרכזיים של שיטת ה-ITS שבעזרתה ניתחתי את נתוני תאונות הדרכים בישראל.
דוגמה: החזרי הוצאות עבור רכישת תרופות אנטי פסיכוטיות למבוטחי מדיקייד במערב וירג'יניה
תכנית מדיקייד היא תכנית ביטוח ממשלתית לבעלי הכנסות נמוכות בארצות הברית, ובין היתר משתתפת בהוצאות לרכישת תרופות של המבוטחים. בתחילת שנות ה-2000, כאשר נכנסו לשוק תרופות אנטי פסיכוטיות מהדור השני, שהן גם יקרות יותר, חלה עלייה משמעותית בהחזרי התשלומים עבור התרופות האנטי פסיכוטיות, כיוון שכ-50% מהמרשמים היו לתרופות מהדור השני. רשויות המדינה אינן יכולות, כמובן, לאסור על הרופאים לרשום לחולים תרופות מסויימות. במדינת מערב וירג'יניה החליטו להתחכם ולהוסיף ביורוקרטיה. החל מאפריל 2003, רופא במדינה שרצה לרשום לחולה שמבוטח במדיקייד תרופת דור שני, היה צריך למלא טופס. הנה גרף המראה את אחוז המרשמים של תרופות דור שני מתוך סך המרשמים לתרופות אנטי פסיכוטיות לאורך זמן, כאשר הקו האנכי המקווקו מסמן את המועד בו הונהגה חובת מילוי הטופס: (( מקור: Law , Ross-Degnan and Soumerai SB, Effect of prior authorization of second-generation antipsychotic agents on pharmacy utilization and reimbursements, Psychiatr Serv. 2008 May;59(5):540-6. ))
 |
ברור לחלוטין שמשהו קרה, אבל הסטטיסטיקה יכולה לתת לנו מבט יותר מעמיק.
הרעיון הוא מאוד פשוט – נעביר שני קווי רגרסיה: קו אחד יותאם לנתונים שלפני השינוי, וקו אחר לנתונים לאחריו (( היישום קצת פחות פשוט, ומייד אפרט למי שמעוניין )). הנה הגרף עם קווי הרגרסיה:
 |
כעת ניתן לראות כמה דברים. ראשית, אחרי ההתלהבות הראשונית נראית מגמה של ירידה, אמנם איטית מאוד, באחוז המרשמים לתרופות דור שני. כמובן שיש לבדוק האם ירידה זו היא מובהקת סטטיסטית (היא לא) ולקבוע האם היא משמעותית (כנראה שלא, אחרת לא היה צריך להפעיל את מדיניות הטופסולוגיה).
שנית, אנו רואים מין ירידת מדרגה קטנה בין הרבעון האחרון שלפני הנהגת המדיניות החדשה והרבעון הראשון לאחר הנהגתה. שוב, ניתן וצריך לבדוק האם זוהי ירידה מובהקת (היא כן) ומשמעותית (לא ברור).
שלישית, ברור לחלוטין שהנהגת המדיניות הביאה לירידה משמעותית ומובהקת באחוז המרשמים לתרופות דור שני.
הקו הירוק מראה את ה-counterfactual, תרחיש ה-"מה היה קורה אילו" לא הונהגה מדיניות מילוי הטפסים. את הצלחת המדיניות מודדים על ידי ההבדל (המוחלט או היחסי) בין מה שקרה בפועל ובין ה-counterfactual.
המודל הסטטיסטי
הדבר הראשון שיש לשים אליו לב הוא שבניגוד למודל רגרסיה רגיל, הנתונים כאן אינם בלתי תלויים אחד בשני. בנתונים של סדרות עיתיות יש בדרך כלל קשר סטטיסטי בין הנתון של נקודת זמן מסויימת והנתון של נקודת הזמן הבאה, ואולי אפילו לנתונים של נקודות זמן רחוקות יותר.התופעה הזאת נקראת אוטוקורלציה. לכן, לפני שמריצים מודלים של רגרסיה, צריך לחקור את הקשרים בין הנתונים לאורך זמן. ברשותכם לא אכנס לפרטים, אך אציין כי קשרים אלה נלקחים בחשבון בהמשך הניתוח.
כמון כן, ציינתי קודם שמעבירים שני קווי רגרסיה, אך אומדים אותם במודל אחד, בן ארבעה פרמטרים: הפרמטר הראשון הוא הגובה בו מתחילה סדרת הנתונים ("החותך"). הפרמטר השני הוא השיפוע, כלומר המגמה, של הנתונים לפני נקודת השינוי. הפרמטר השלישי הוא הקפיצה או הפער בין הנקודה אליה הגיעה הסדרה ממש לפני השינוי ובין הנקודה הראשונה אחרי השינוי. הפרמטר האחרון הוא הרבה פחות אינטואיטיבי: זהו ההפרש בין המגמה של הנתונים לפני השינוי והמגמה שלאחר השינוי. השרטוט הבא מנסה להבהיר את המשמעות של ארבעת הפרמטרים ((השרטוט נלקח מהשקפים של הקורס Policy Analysis using Interrupted Time Series שזמין ברשת באתר edX))
|
|

לאחר שאומדים את הפרמטרים של המודל אפשר לבדוק בעזרת שיטות סטנדרטיות האם השינויים הם מובהקים, וכן להעריך האם הם גם משמעותיים.
נשלח: 27 ביולי, 2018. נושאים: מה אומרת הסטטיסטיקה.
תגובות: 1
| טראקבק
איך חוזים תוצאה של מונדיאל?
עכשיו, כשנאלמה תרועת הפסטיבלים והמונדיאל הסתיים, זה זמן טוב לדבר על כל המודלים שסיפקו תחזיות מונדיאל ועל מודלים של תחזיות בכלל.
ברשימה זו אסקור את הבסיס למודלים שניסו לחזות את תוצאות המונדיאל, ומשם אעבור לדיון בחלק מהתכונות של מודלים לחיזוי, במשמעות של החיזוי ובמגבלות של המודלים האלה.
איך חוזים תוצאה של מונדיאל?
הסקירה הזו מתבססת בחלקה על המאמר הזה שפורסם באקונומיסט לפני פתיחת המונדיאל של 2018 ((תודה לצליל אברהם שהפנתה את תשומת ליבי אליו)).
כדי לחזות את התוצאה של המונדיאל (או כל טורניר ספורט אחר) יש צורך במספר שלבים. ראשית, צריך לדרג באופן כלשהו את הנבחרות/קבוצות המשתתפות בטורניר ואת הבדלי הרמות ביניהן. בשלב השני צריך לספק הערכה/חיזוי לתוצאות של משחקים ספציפיים ((גרמניה מול מקסיקו, מישהו? תיכף נדבר על זה)), ובשלב השלישי לנסות לחזות על סמך החיזויים של תוצאות המשחקים את המנצחת הסופית. המאמר שפורסם באקונומיסט מתעמק בעיקר בשלב הראשון.
שלב ראשון: דירוג הנבחרות
יש שתי דרכים לדרג את האיכות של נבחרת או קבוצת ספורט: על ידי הערכת ביצועי הקבוצה, או על ידי הערכת ביצועי השחקנים.
להערכת ביצועי הקבוצה משתמשים בעיקר במודלים מסוג Elo , מודל שפותח במקור עבור משחק השחמט. הרעיון הוא שכל קבוצה מקבלת ניקוד על כל משחק שהיא שיחקה, אבל בניגוד לליגה או לטורנירים שבהם מקבלים 3 נקודות על כל ניצחון, לא משנה באיזה משחק, ב- Elo הניקוד משתנה בהתאם ליריבה, מיקום המשחק, חשיבותו, וכדומה. אם למשל גרמניה מנצחת את סעודיה במשחק ידידות שנערך בלוורקוזן, הניצחון הזה לא שווה הרבה נקודות, כי היריבה נחותה, המשחק לא ממש חשוב, וגרמניה שיחקה במגרש הביתי. לעומת זאת, ניצחון על ברזיל, במשחק שנערך בברזיל, במסגרת חצי הגמר של המונדיאל, שווה הרבה מאוד נקודות. יש כל מיני וריאציות למודל, מה שמסביר חלק מההבדלים בניבויים השונים. למודלים שונים יש מפתח נקודות שונה, ויש גם מודל שנותן ניקוד לא על פי תוצאת המשחק אלא על פי מספר השערים שהובקעו, וכך ניצחון בתוצאה 7:1 שווה הרבה יותר מניצחון 1:0. כמו כן, צריך להחליט על איזה אופק זמן מסתכלים. יכול להיות משחק ששוחק במונדיאל מקסיקו 70 או אפילו בדרום אפריקה ב-2010 כבר לא ממש משמעותי. עם זאת, באחת הכתבות תואר מודל שלקח בחשבון את כל התוצאות מאז המונדיאל הראשון שנערך ב-1930. אני מניח שהמודלים משקללים את המשמעות של כל משחק בהתחשב בזמן שעבר.
הדרך השנייה היא להעריך כל שחקן לחוד, ואז לקבל הערכה של הקבוצה כסך כל שחקניה. יש כל מיני דרכים לעשות את זה. אפשר למדוד את הביצועים של כל שחקן בכל משחק (כמה מסירות טובות הוא מסר, כמה תיקולים מוצלחים וכדומה). לדעתי צריך לקחת בחשבון גם פעולות שהשחקן לא עשה ואולי היה צריך לעשות (לא ברור לי אם יש בכלל נתונים כאלה). כמו כן, יש דברים ששחקנים תורמים לקבוצה ולא ניתנים למדידה – מנהיגות למשל.
דרך אחרת היא לבדוק מה היו ביצועי הקבוצה כשהשחקן שיחק בהרכב ומה הם היו כשהוא לא שיחק. בכדורגל זה פחות יעיל כי יש יחסית מעט משחקים, יש מעט חילופים, ובדרך כלל אין הרבה שינויים בהרכבים. עם זאת, זו שיטה מאוד מקובלת ויעילה בענפים כמו כדורסל ובייסבול.
ראיתי באחת הכתבות גם מודל שהכניס לשקלול את משכורות השחקנים. המודל הזה חזה שצרפת תזכה בטורניר, ואנחנו כבר יודעים שהוא צדק. זה לא בהכרח אומר שהוא מודל טוב. אם יש הרבה מודלים, אז הסיכוי שאיזשהו מודל יצדק הוא לא נמוך. זה כמו בלוטו. הסיכוי שאתה תזכה בפרס הגדול הוא קטן, אבל הסיכוי שמישהו יזכה הוא מאוד גבוה. עם זאת, אין להבין מדבריי כי אני חושב שזה מודל לא טוב. האמת היא שאי אפשר לקבוע.
אפשר גם לשקלל את את הערכת הנבחרת עם הערכת השחקנים, ויש כל מיני שקלולים: 50-50, 75-25 וכולי. זה כנראה לא כל כך משנה. לפחות לפי הנתונים שהובאו באקונומיסט, יש מתאם גבוה בין שתי שיטות ההערכה:
 |
שלב שני: חיזוי תוצאות של משחקים
אחרי שיש לנו מדד שמעריך את האיכות של כל נבחרת, אפשר להתחיל לדבר על חיזוי תוצאות של משחקים. שוב, יש כל מיני דרכים לעשות את זה, אבל העיקרון דומה. לוקחים נתונים של המון משחקים שרלוונטיים בעינכם. אתם יכולים לקחת את הנתונים של המשחק בן גרמניה וסעודיה שנערך בלוורקוזן ביוני 2018 (גרמניה ניצחה 2:1), וגם את המשחק בין גרמניה והולנד בגמר מונדיאל 1974 (מצטער שאני משבית שמחות). לכל משחק הנתונים יכולים לכלול כל מיני פרטים שנראים חשובים למי שבונה את המודל – כגון הערכת הנבחרות לפי מודל Elo כזה או אחר, מקום משחק, חשיבותו, מסורת ניצחונות, מזג האוויר, המשכורת של השחקנים, או מספר הנעליים של השוער. אלה הם המשתנים המסבירים. לכל משחק יש גם תוצאה – זה המשתנה המוסבר, ויש שלוש תוצאות אפשריות. אפשר לשפוך את כל הנתונים לתוך אלגוריתם שמיישם מודל – רגרסיה לוגיסטית, random forest, דיפ לרנינג, מה שבא לכם.
לאחר שאמדתם את הפרמטרים של המודל (( או כמו שאנשי המשין לרנינג אוהבים להגיד – "אימנתם אותו")) ווידאתם שהוא פועל היטב גם על נתונים ששמרתם בצד ולא נכנסו למודל, אתם יכולים לקחת את הנתונים של נבחרת גרמניה ושל נבחרת מקסיקו, להפעיל עליהם את המודל שלכם, ולקבל תוצאה. התוצאה תהיה בעצם שלוש הסתברויות: ההסתברות שגרמניה תנצח במשחק, ההסתברות שמקסיקו תנצח, וכמובן גם את ההסתברות שהמשחק יסתיים בתיקו. חשוב לזכור שאלה לא הסתברויות "אמיתיות". אלה הם אומדנים להסתברויות, שקיבלתם מהמודל שלכם, והם מתבססים על כל ההנחות שהנחתם בדרך.
שלב שלישי: חיזוי מהלך הטורניר
עכשיו מתחיל הכיף האמיתי. אני מניח שכל מודל שהוא שניסה לחזות את תוצאת המשחק בין מקסיקו לגרמניה נתן הסתברות גבוהה לניצחון של גרמניה, הסתברות יותר נמוכה לתיקו, ולניצחון של מקסיקו ניתנה ההסתברות הנמוכה ביותר. אבל דברים יכולים לקרות (ואכן קרו). מה עושים? סימולציה.
נניח לצורך הדוגמה שההסתברויות שהפיק המודל היו 70% לניצחון גרמניה, 20% לתיקו, ו-10% לניצחון מקסיקו. שמים בתוך שק 10 כדורים: 7 לבנים, 2 ירוקים, וכדור שחור אחד. מערבבים טוב טוב את הכדורים ומוציאים כדור אחד. אם הוא לבן, נגיד שגרמניה "ניצחה", אם הוא ירוק נגיד שהמשחק "הסתיים בתיקו", ואם הכדור שהוצאנו הוא שחור נגיד שזה היה יום שחור לגרמניה. אפשר לעשות את זה גם בעזרת מחשב כמובן.
צריך לזכור שבבית שבו שיחקו גרמניה ומקסיקו היו עוד שתי נבחרות ובסך הכל שוחקו בו שישה משחקים. אז עושים את התרגיל הזה לכל אחד מששת המשחקים, וכשיש לנו את כל תוצאות המשחקים שהתקבלו בסימולציה, מקבלים את טבלת הבית, ואת שתי הנבחרות שעלו לשלב הבא.
את התרגיל הזה עושים לכל הבתים בשלב המוקדם, ובסיומו "נדע" מי הן 16 הנבחרות שעלו לשמינית הגמר, ואיזה נבחרת תשחק מול איזה נבחרת. את התוצאות של המשחקים אנחנו יכולים לחזות באותו אופן, ומשם "נדע" מה יהיו משחקי רבע הגמר וכך הלאה. בסופו של כל התהליך נקבל את הזוכה.
כל התוצאות שקיבלנו מתבססות של הגרלות ושליפה וירטואלית של כדורים מתוך שקים. אם נבצע שוב את התהליך מההתחלה, סביר להניח שנקבל תרחיש אחר ותוצאה שונה. נו פרובלם. נחזור על התרגיל הזה המון פעמים, 10000 נניח, או מיליון, ונחשב איזשהו ממוצע של כל התרחישים שהגרלנו. למשל, אם ב-900 מתוך 10000 תרחישים קיבלנו שגרמניה זכתה בסופו של דבר, נאמוד את הסיכוי שגרמניה תזכה במונדיאל ב-900 חלקי 10000 שהם 9%. החיזוי האולטימטיבי של הזוכה במונדיאל הוא הנבחרת שניצחה ברוב התרחישים מבין ה-10000.
אם המודל שממנו התחלנו הוא מודל טוב, והנתונים שבהם השתמשנו כדי לאמוד את הפרמטרים של המודל הם נתונים טובים, אז גם התחזיות יהיו טובות. אבל…
נקודת תורפה: הנחת אי-תלות
אבל יש כאן בעיה גדולה: כל מה שתואר עד כאן מניח שהמשחקים בלתי תלויים, והם לא. תוצאה של משחק אחד בהחלט יכולה להשפיע על תוצאה של משחק אחר. אם למשל, נבחרת הבטיחה את עלייתה לשמינית הגמר אחרי שני משחקים, ייתכן כי השחקנים החשובים, הכוכבים, יקבלו מנוחה, כי אין טעם להשקיע מאמצים במשחק שלא משנה כלום. אירוע כמו פציעה של שחקן במשחק בהחלט יכול להשפיע על המשחק הבא. קבוצה שהשקיעה הרבה מאוד מאמץ כדי לנצח בשמינית הגמר (הארכה, יריבה קשה במיוחד) תגיע מותשת יותר למשחק הבא, ויד עוד הרבה דוגמאות. כל המודלים לטווח ארוך (שמנסים לחזות מי תזכה בטורניר לפני שהוא התחיל) לא יכולים לקחת את כל הפרמטרים האלה בחשבון. כאן יש יתרון ברור לסוכנויות ההימורים, שיכולות לעדכן את אמדני הסיכויים ושערי ההימורים ממשחק למשחק.
למה בכלל צריך סימולציה?
בדף של הבלוג בפייסבוק, Mickey Ktv שאל את השאלה הזו: "מה המשמעות של ביצוע הסימולציה? הרי אם יש לנו הסתברות מסויימת לכל משחק, אנחנו יכולים לפי זה לחשב את ההסתברות של כל קבוצה לנצח. בגלל חוק המספרים הגדולים, תוחלת הסימולציה צריכה לצאת קרובה מאוד להסתברות שמחושבת 'ידנית'. האם זה בגלל שיותר פשוט להריץ סימולציה במחשב מאשר לחשב את ההסתברות? (למרות שבמידה שקולה ניתן לבנות מודל שמחשב את ההסתברות עצמה)"
בתיאוריה אין שום בעיה לקחת נייר ועיפרון ולחשב את כל ההסתברויות וההסתברויות המותנות. אבל הנה ההבדל בין התיאוריה והמציאות. בכל בית יש ארבע נבחרות, ולכן יש 24 אפשרויות שונות לתוצאה הסופית של טבלת הבית. אבל בואו ניתן הנחה – מה שמעניין זה מיהן שתי הנבחרות שמסיימות במקום הראשון והשני, ולכך יש רק 12 תוצאות אפשריות. פרט למקרים מאוד נדירים, לכל התוצאות האלה יש הסתברות חיובית. יש 8 בתים מוקדמים, ולכן מפר התרחישים האפשריים לשמינית הגמר הוא 12 בחזקת 8. זה יוצא קצת פחות מ-430 מיליון (429981696). אז קצת קשה לעשות את זה עם נייר ועיפרון. גם אם נכתוב תכנית מחשב שתבצע את כל החישובים, לא סביר שהיא תסיים לרוץ לפני סיום המונדיאל הבא… במקרה כזה הדרך המעשית היחידה לאמוד את ההסתברויות באופן יעיל היא בעזרת סימולציה.
מה עשו המודלים?
בטבלה שפורסמה באקונומיסט יש תחזיות של כמה מודלים. הסיכויים של ברזיל נעו בין 13 ל-32%, של גרמניה בין 5 ל-16%, של צרפת בין 5 ל-11%, ושל קרואטיה בין 1 ל-3%. שימו לב שהאחוזים בטורים לא מסתכמים ל-100%. מכאן שהמודלים האלה נתנו הסתברויות חיוביות לזכייה של נבחרות "פחות נחשבות" – אולי מצרים או קמרון.
 |
האם המודלים האלה הצליחו או נכשלו? זה תלוי כמובן איך מגדירים הצלחה או כישלון. המודל של Goldman Sachs, למשל, נתן לצרפת הסתברות של 11% לזכות. הוא לא אמר שצרפת לא תזכה. גם מאורעות שהסתברותם 11% מתרחשים לפעמים. הוא גם נתן לברזיל הסתברות של 19% לזכות, או במילים אחרות, אמר כי יש הסתברות של 81% שברזיל לא תזכה. צדק או לא צדק? (( יש הרבה דרכים להעריך את האיכות של מודלים האופן כמותי. לא אכנס לפרטים))
על המשמעות של המודלים
הבעיה של כל המודלים לתחזיות, מכל סוג שהוא, ולכל מה שאתם רוצים לחזות, היא שהם מנסים לחזות משהו שעוד לא קרה, כלומר את העתיד. ולחזות את העתיד, כפי שציין בצדק נילס בוהר, זה קשה מאוד. ואין הבדל עקרוני בין תחזית למשחק כדורגל בודד, לתוצאה הסופית של מונדיאל שלם, למזג האוויר של מחר ((אם אתם לא בישראל, כמובן)), או לשאלה החשובה מאוד האם אני אקנה באמזון ספר שיציע לי האלגוריתם כאשר אכנס לאתר הזה בפעם הבאה. כל המאורעות האלה הם מאורעות חד פעמיים. תסלחו לי על האמירה הבוטה, אבל התחזית של המודל היא בסך הכל ניחוש אינטליגנטי (( זו לא תובנה מקורית שלי, שמעתי אותה ממורי ורבי פרופ' צבי גילולה)).
בעולם שלנו יש שונות אינהרנטית, או כמו שכתבתי למעלה, דברים קורים. מה קרה במשחק של גרמניה מול מקסיקו? קרו המון דברים, ואת רובם אנחנו אפילו לא יודעים. אולי לאחד השחקנים של גרמניה כאב הראש, ושחקן אחר סתם בא במצב רוח לא טוב, ואילו השוער של מקסיקו מאוד נהנה בארוחת הבוקר ועקב כך חש אנרגיות חיוביות. לך תדע. מצד שני, בעשרים השנים האחרונות גרמניה מנצחת באופן עקבי ולאורך זמן ב-75% מהמשחקים שלה, ולכן אני מוכן להתערב שאם גרמניה ומקסיקו יישחקו 100 משחקים, גרמניה תנצח לפחות ב-75 מהמשחקים האלה (( על איזה סכום להתערב? צריך כמובן לחשב את ההסתברות שגרמניה תנצח ב-75 משחקים לפחות אם הסיכוי שלה לנצח במשחק בודד הוא 75%)).
וזו הפרשנות שאני נותן לחיזוי – פרשנות שכיחותנית (( סטטיסטיקאים אחרים ייתנו אולי פרשנויות אחרות, ואני לא אכנס כאן לפרטים)).
לפי הפרשנות הזאת, אם אומרים לכם שמחר יש 30% סיכוי לגשם ((כמובן בהנחה שאתם לא בתל אביב אלא בלונדון )), המשמעות היא שבשלושים אחוז מהימים שדומים ליום שיהיה מחר ירד גשם. שימו לב שהפרשנות לפיה ב-30% ממשך היום יורד גשם אינה נכונה – זה כמו להגיד שברזיל תזכה ב-19% מהגביע. ואם המודל של אמזון חוזה שיש סיכוי של 20% שאקנה את הספר שהאלגוריתם מציע לי – פירוש הדבר הוא ש-20% מהאנשים שדומים לי יקנו את הספר.
ומכאן נובעת המגבלה העיקרית של כל המודלים: טיב החיזוי מוגבל על ידי כמות המאורעות. לחזות תוצאה של אירוע חד פעמי כמו המונדיאל זה קשה מאוד. אם נתחיל מחר את כל המונדיאל מחדש עם אותן הנבחרות, אף אחד לא יכול להבטיח לנו שתתקבל אותה התוצאה.
אם לעומת זאת, אנחנו מנסים לחזות תוצאות של הרבה מאורעות דומים ו/או נשנים, התחזיות הופכות להיות יותר אמינות, או כפי שאני מעדיף לומר, יותר סבירות. היו בלונדון הרבה ימים כמו מחר, וב-30% מהם ירד גשם, ולכן התחזית כי מחר יש סיכוי של 30% לגשם היא סבירה. ולאמזון יש מיליון לקוחות כמוני ((רק שלא קוראים להם יוסי לוי, ואם יש ביניהם יוסי לוי אחר, אז הוא חיקוי זול)), ואם המודל שמציע את הספר הוא מודל טוב, אז 20% מהאנשים האלה יקנו אותו, ובעלי המניות של אמזון מרוצים.
נשלח: 15 ביולי, 2018. נושאים: דטה סיינס, מה אומרת הסטטיסטיקה, ספורט.
תגובות: 2
| טראקבק
תאונות הדרכים בישראל – לפני ואחרי מינוי של ישראל כץ לשר התחבורה
מה קורה עם תאונות הדרכים בישראל?
בתחילת יולי 2018 שר התחבורה ישראל כץ צייץ בשמחה בטוויטר (יש גם צילום מסך למקרה שהציוץ יימחק בדרך פלא) ובישר על "ירידה דרמטית של 22% (!!!) במספר ההרוגים בתאונות הדרכים, במחצית הראשונה של 2018" ((תוך כדי השתלחות בעמותת "אור ירוק", אבל זה סיפור אחר )). הירידה באמת משמחת, ללא ציניות. אבל האם זו ירידה חד פעמית, תחילה של מגמה, או תוצאה של מגמה? ומה חלקו של השר בירידה המבורכת הזאת? את חלקו של השר במה שקורה בחצי שנה אכן קשה להעריך, אולם ניתן לראות מה קורה לאורך זמן.
לשם כך שלפתי ממאגר הנתונים של הלשכה המרכזית לסטטיסטיקה את נתוני תאונות הדרכים עם נפגעים משנת 2003 ועד שנת 2017 שהתרחשו בתחומי הקו הירוק.
כאן עלי להסביר כי הנתונים של הלמ"ס מתייחסים רק לתאונות דרכים עם נפגעים בהן לפחות אחד מהמעורבים בתאונה נהרג או אושפז. חומרת התאונה נקבעת לפי חומרת הפגיעה של הנפגע החמור ביותר. אם יש הרוג אחד לפחות, התאונה מסווגת כקטלנית. אם הפגיעה החמורה ביותר היא לאדם שנפצע קשה ואושפז, התאונה מסווגת כתאונה קשה. במקרהtraffic_accidents שהפגיעה החמורה ביותר היא לאדם שנפצע פציעה בינונית או קלה, התאונה מסווגת כתאונה קלה. אם לא היו נפגעים, או שהיו נפגעים אך אף אחד מהם לא אושפז, התאונה לא נכנסת לסטטיסטיקה.
עכשיו אפשר להעיף מבט בנתונים, ולראות, למשל, כי ב-2003 היו בישראל 413 תאונות דרכים קטלניות, ובמשך השנים המספר ירד ל-295 תאונות קטלניות בשנת 2017. אי אפשר להכחיש כי אכן היה שיפור במצב.
השיפור אפילו יותר משמעותי ממה שהוא נראה במבט ראשון: ב-2017 היו הרבה יותר מכוניות מאשר ב-2003, והן נסעו הרבה יותר קילומטרים. אפשר לראות זאת בעזרת נתוני הנסועה. הנסועה היא סך כל הקילומטרים שנסעו כל כלי הרכב במשך השנה. הרכב שלי עובר כ-15 אלף ק"מ בשנה, וזו תרומתו לנסועה. מישהו אחר אולי נוסע 50 אלף ק"מ בשנה, ויש כאלה שאף נוסעים מרחקים יותר ארוכים. אם מחברים את סך הקילומטראז של כל כלי הרכב בשנה מסויימת מקבלים את סך הנסועה לאותה השנה. שלפתי מאתר הלמ"ס ((מתוך השנתונים הסטטיסטיים)) גם את אומדני הנסועות ((שמבוססים על מדגמים)) לשנים 2003 עד 2016. הנתון של 2017 אינו זמין עדיין ואמדתי אותו בעזרת מגמת העלייה לאורך השנים. ב-2003 הנסועה בישראל הייתה שווה ל-38.9 מיליארד ק"מ, וב-2017 היא נאמדה ב-57.7 מיליארד ק"מ. מכאן שב-2013 היו כ-10.6 תאונות דרכים קטלניות לכל מיליארד ק"מ, וב-2017 היו רק 5.1 תאונות דרכים קטלניות לכל מיליארד ק"מ. זו ירידה מבורכת של מעל 50%.
שאלה מעניינת היא איך זה קרה ולמה, אולם כדי לענות על שאלות אלה יש צורך בנתונים נוספים ובניתוח נרחב. יש כאן פוטנציאל לעבודת מאסטר.
אני אנסה לתאר בעזרת מודל ITS מה קרה לאחר שישראל כץ נכנס לתפקידו כשר התחבורה במרץ 2009. לא סביר לדרוש משר שינוי מיידי בתחומי אחריותו עם כניסתו לתפקיד, ולכן קבעתי את נקודה השינוי בתחילת 2010. הנתונים עד 2009 (כולל) נזקפים לזכותם (או לחובתם) של שרי התחבורה הקודמים ((אביגדור ליברמן – 2003 עד 2004, מאיר שטרית – 2004 עד 2006, ושאול מופז – 2006 עד 2009)).
נתבונן תחילה בנתוני סך תאונות הדרכים. ניתן לראות כי בשנים 2003 עד 2009 הייתה מגמת ירידה בשיעור הכולל של תאונות דרכים עם נפגעים. .
 |
אנו רואים כי מגמת הירידה שהייתה בין 2003 ל-2009 נמשכת גם בשנים 2010-2017, אך המגמה הואטה במקצת וקצב הירידה נמוך יותר. השינוי מובהק סטטיסטית. מה המשמעות של השינוי? אילו מגמת הירידה הייתה נמשכת לפי הקו הירוק, הוא ה-counterfactual, היו לנו ב-2017 154.6 תאונות למיליארד ק"מ, ובסך הכל קצת יותר מ-8900 תאונות עם נפגעים. בפועל היו 12700 תאונות עם נפגעים ב-2017, כלומר 42% יותר, ובמספרים מוחלטים מדובר בעוד 3800 תאונות עם נפגעים שהיו יכולות להימנע לו מגמת הירידה הייתה ממשיכה ולא מואטת.
כעת נבחן לחוד את סוגי התאונות השונים. נתחיל בתאונות הדרכים ה-"קלות", שבהן היה לכל היותר פצוע בינוי או קל שאושפז: (( ויקיפדיה: " הוא מי שנשקפת סכנה לחייו אם לא יקבל טיפול רפואי. כלומר, מי שכעת יש להשקיע מאמץ קטן כדי להציל את חייו, אך אם יוזנח, יידרש מאמץ גדול כדי להציל את חייו. פצוע בינוני יכול להיות גם מי שאין נשקפת סכנה ממשית לחייו, אך קיים חשש כבד לנכות משמעותית או איבוד איבר (גפיים, לרוב)." ))
 |
מאחר ורוב תאונות הדרכים עם נפגעים מסווגות כקלות (85-90%, תלוי בשנה), אנו רואים כאן תמונה דומה לזו שראינו כשהסתכלנו על הסך הכולל של תאונות הדרכים. יש בלימה במגמת הירידה של שיעור תאונות הדרכים הקלות החל מ-2010. גם כאן השינוי בקצב מגמת הירידה מובהק סטטיסטית. אילו התקיים תרחיש ה-counterfactual, היינו צפויים לראות ב-2017 כ-8730 תאונות "קלות", בעוד שבפועל היו 10579 תאונות כאלה, 21% יותר.
נמשיך אל תאונות הדרכים הקשות. רוב הירידה בכמות תאונות הדרכים הקשות הייתה בין השנים 2003 ל-2009. מגמת הירידה שהייתה הזו נבלמה, ואף גרוע מכך: מספר התאונות הקשות החל מ-2010 נמצא במגמת עליה (כל השינויים מובהקים סטטיסטית ומשמעותיים):
 |
שימו לב כי אילו מגמת הירידה בשיעור תאונות הדרכים הקשות הייתה נמשכת באותו קצב גם אחרי 2009, אז ב-2017 לא היו אמורות להתרחש תאונות דרכים קשות בכלל. זה כמובן לא ריאלי, יכול להיות שהגענו כבר לקו התחתון של שיעור התאונות הקשות שמתחתיו אי אפשר לרדת או שאנחנו מאוד קרובים אליו. מה מידת האחריות של שר התחבורה כאן? לדעתי אי אפשר להטיל במקרה הזה את כל האחריות על שר התחבורה הנוכחי. עם זאת, אין להסיק מכך שאין לו אחריות כלל. יש לו אחריות מיניסטריאלית, ורצוי וצריך לבדוק את מידת האחריות שלו על ידי בחינת נתונים נוספים.
לבסוף נתבונן בנתוני תאונות הדרכים הקטלניות:
 |
רוב הירידה של ה-50% שציינתי קודם בשיעור תאונות הדרכים הקטלניות שציינתי קודם הייתה בין השנים 2003 ל-2009 (בשנים האלה הייתה ירידה של כ-45% בשיעור התאונות הקטלניות). מגמת הירידה בשיעור תאונות הדרכים הקטלניות נבלמה. אמנם עדיין יש ירידה בשיעור תאונות הדרכים הקטלניות גם אחרי 2009, אך קצב הירידה נמוך באופן משמעותי (ומובהק סטטיסטית). שוב שימו לב כי אילו מגמת הירידה הייתה נמשכת באותו קצב גם אחרי 2009, אז ב-2017 לא היו אמורות להתרחש תאונות דרכים קטלניות בכלל. גם כאן, אי אפשר להטיל את כל האחריות על שר התחבורה הנוכחי. האם הגענו כבר לקו התחתון של שיעור התאונות הקטלניות שמתחתיו אי אפשר לרדת? דעתי האישית היא שניתן לעשות עוד. בשוודיה חושבים שהמטרה של אפס תאונות דרכים קטלניות היא ריאלית.
ניתן לטעון כי רואים כאן סוג של "טרייד אוף" בשנים 2010 והלאה: לאחר שמוצתה הירידה החדה של תאונות קטלניות וקשות בשנים 2003 עד 2009, יש עליה מסויימת במספר התאונות הקשות, כיוון שחלק מתאונות עם פוטנציאל להיות קטלניות הסתיימו "רק" בפציעות קשות. עם זאת, יש לזכור כי שיעור התאונות הקשות גבוה פי 5 עד 6 משיעור התאונות הקטלניות. בין 2010 ל-2017 חלה בסך הכל ירידה כוללת של כתאונת דרכים קטלנית אחת למיליארד ק"מ, אך עליה של כחמש תאונות דרכים קשות למיליארד ק"מ. גם אילו כל הירידה בתאונות הדרכים הקטלניות הייתה הופכת לעליה בכמות תאונות הדרכים הקשות, עדיין צריך להסביר מאין באה העלייה של עוד ארבע תאונות דרכים קשות למיליארד ק"מ.
לסיכום: בתקופת כהונתו של ישראל כץ כשר התחבורה, עד סוף 2017, הואטה מגמת הירידה החדה בשיעורי תאונות הדרכים עם נפגעים שהתרחשה בין 2003 ל-2009. הירידות בשיעורי תאונות הדרכים הקשות והקטלניות נבלמו כמעט לחלוטין, ואף יש מגמת עליה בכמות תאונות הדרכים הקשות. ניתן להסביר רק חלק קטן (כ-20%) מכמות העלייה במספר התאונות הקשות על ידי ההשערה כי חלק מהתאונות עם פוטנציאל קטלני הסתיימו בפגיעות קשות בלבד. יש צורך לבדוק מה היו הסיבות לשינויי המגמות, ומה חלקו של שר התחבורה ומדיניות בכך, ולשם כך יש צורך בנתונים נוספים ובניתוח סטטיסטי יותר מקיף מהניתוח הבסיסי שהוצג כאן. ייתכן כי לא כל השינויים נבעו מפעילות השר ומדיניותו, אך עדיין יש לו אחריות מיניסטריאלית מלאה למצב תאונות הדרכים בשנות כהונתו.
נשלח: 6 ביולי, 2018. נושאים: מה אומרת הסטטיסטיקה, על סדר היום.
תגובות: 15
| טראקבק
סקרים בקרב יהודים ולא יהודים: מדגם שכבות
בחודשים האחרונים, בעקבות ביקורת פוליטית בעיקרה ((ומוצדקת, לדעתי)), עברו אמצעי התקשורת בישראל לפרסם סקרי דעת קהל בהם נסקרת גם דעתם של ערביי ישראל, בניגוד לנוהג הקודם שבו נערכו סקרי דעת הקהל בקרב "האוכלוסייה היהודית הבוגרת". סקרים אלה מבוססים על עריכה של שני סקרים נפרדים, אחד בקרב האוכלוסייה היהודית והשני בקרב האוכלוסייה הערבית, ושיקלול תוצאות שני הסקרים. מתודולוגיה זו ידועה בשם "מדגם שכבות".
הרעיון של מדגם שכבות אכן פשוט מאוד, וכבר הוסבר למעשה בפיסקה הקודמת. אולם יש מספר שאלות מעניינות שאנסה לתת להן תשובות כאן. לאחר שאסביר את העקרונות אנתח דוגמה ספציפית של מדגם כזה שהוצג בערוץ 10. המסקנה שלי היא כי במקרה הזה אין תועלת במדגם מפוצל, ורצוי לערוך מדגם יחיד בקרב כל האוכלוסייה.
מתי כדאי לערוך מדגם שכבות?
בעקרון כדאי לערוך מדגם שכבות כאשר האוכלוסייה הנדגמת (לא בהכרח בני אדם), מתחלקת למספר קבוצות הנקראות שכבות. מדגם שכבות יעיל יותר ככל שההבדלים בין השכבות משמעותיים יותר, ומאידך ההבדלים בין הפרטים בתוך השכבות קטנים יותר. במונחים סטטיסטיים נאמר כי השונות בין השכבות גדולה, בעוד שהשונות בתוך השכבות נמוכה.
לדוגמה, נניח שאנחנו רוצים לאמוד את מחירה של דירת 4 חדרים בתל אביב. דרך אחת היא לקחת מדגם של דירות ברחבי העיר. אולם, מאחר ויש שוני רב בין שכונות העיר (תחשבו על רמת אביב ג מול נווה עופר, למשל), ייתכן וכדאי לקחת מדגם קטן יותר בכל אחת משכונות העיר ולשקלל את תוצאות המדגמים. זאת גם מכיוון שבתוך כל שכונה ההבדלים היחסיים בין דירות דומות בתוך השכונה הינם יחסית קטנים בהשוואה להבדלים בין כלל הדירות בכל העיר.
איך מבצעים את המדגם?
לאחר שנקבעו השכבות, אפשר לדגום מדגם הסתברותי פשוט ("מדגם רגיל") בתוך כל אחת מהשכבות, אם כי אפשר כמובן לבצע בתוך כל שכבה מדגמים מורכבים יותר.
איך משקללים את התוצאות?
את התוצאות משקללים על פי גדלי השכבות. לדוגמה, נניח שבעיר מסויימת יש שלושה איזורים: צפון, מרכז ודרום, ואנו מעוניינים לאמוד את השכר הממוצע בעיר. בצפון מתגוררים 5000 איש הנכללים במדגם, במרכז 15000 ובדרום 30000. נניח שמסיבה כלשהי הוחלט כי גודל המדגם בשכבת הצפון יהיה 500 איש, במרכז 1000, ובדרום 250 ((אגיע לכך עוד מעט)). מקבלים כי השכר הממוצע בכל אחד מהאיזורים הוא 15,000 ₪ בצפון, 5000 ₪ במרכז, ו-9000 שח בדרום. מכיוון שבצפון מתגוררים 10% מהתושבים (5000 מתוך 50000) במרכז 30% (15 אלף מתוך 50 אלף) ובדרום 60% מהתושבים (30 אלף מתוך 50 אלף), האומדן לשכר הממוצע הכולל הוא לכן 8700 ₪:

האינטואיציה לחישוב: השכר הממוצע בשכבת הצפון הוא 15000 ₪. לא משנה איך הוא נאמד, הפרשנות של הנתון היא כי כל תושב בשכבה מרוויח "בממוצע" 15000 ₪, ולכן 5000 תושבים מרוויחים בסך הכל 5000 כפול 15000 ₪, כלומר 75 מיליון שח, באותן אופן סך כל השכר באיזור המרכז הוא 6000 ₪ כפול 15000 כלומר 90 מיליון ₪, ובאיזור הדרום סך השכר של כל התושבים הוא 9000 ₪ כפול 30000 תושבים, וזה יוצא 270 מיליון ₪. כעת מחברים את כל הסכומים ומקבלים 435 מיליון ₪, ומחלקים את הסכום הזה במספר התושבים, 50000, ומקבלים 8700. ((קחו מחשבון ותבדקו)).
איך מחשבים את טעות הדגימה?
טעות הדגימה תלויה בשונות הכוללת של המדגם, ובגודל המדגם. ככל השונות הכוללת גדולה יותר, כך טעות הדגימה גדולה יותר. מצד שני, אפשר להקטין את טעות הדגימה לגודל הרצוי לנו על ידי הגדלת גודל המדגם. אם השונות הכוללת וגודל המדגם הכולל נתונים, חישוב טעות הדגימה הוא סטנדרטי – מכפילים את סטיית התקן של הממוצע בקבוע מההתפלגות הנורמלית, בדרך כלל 1.96 כדי לקבל רווח סמך של 95%.
איך קובעים את גודל המדגם?
הבעיה היא כמובן שכדי לקבוע את גודל המדגם צריך לדעת את השונות הכוללת ואת השונות בתוך כל שכבה, וכדי לדעת מה השונויות האלה צריך לקחת מדגם. בעיה זו, אגב, אינה ייחודית למדגם שכבות אלא לכל מדגם שהוא.
יש מספר דרכים להתגבר על הבעיה. אפשר לבצע מדגם מקדים קטן יחסית (פיילוט) כדי לקבל הערכה גסה לשונות. אפשר להסתמך על ידע קודם, ואפשר לתכנן על פי התרחיש הגרוע (worst case scenario) – דבר המקובל בעיקר כאשר מנסים לאמוד פרופורציות, כמו למשל שיעור התומכים בעמדה מסויימת. אפשרות נוספת היא לקבוע את גודל המדגם כגודל המדגם הדרוש כדי להבטיח את גודל טעות הדגימה המירבית במדגם רגיל ללא שכבות.
את השונות הכוללת מחשבים באופן דומה לחישוב בממוצע, כלומר על ידי שקלול השונויות בכל אחת מהשכבות בגורם שקלול הקשור בגודל היחסי של השכבה. עם זאת, גורמי השקלול אינם אינטואיטיביים כמו בשקלול הממוצעים של השכבות. השקלול מתבסס על ריבועי המשקלים של השכבות. בדוגמה שלנו, המשקל של שכבת הצפון היה 10% או 0.1, ולכן המשקל שלה בשקלול השונויות יהיה 0.1 בריבוע, כלומר 0.01, וכך לשאר השכבות. שימו לב כי המשקלים כעת לא מסתכמים ל-100%.
לאחר שיש בידינו את אומדני השונויות אפשר לחשב מתוכן את גודל המדגם הדרוש (אני אחסוך מכם את הנוסחה).
דרך אחרת לקבוע את גודל המדגם היא לקבוע בנפרד את גודל המדגם בכל שכבה, וגודל המדגם הכולל יהיה לכן סכום גדלי כל המדגמים השכבתיים. דרך זו בדרך כלל אינה יעילה.
איך קובעים את גדלי המדגם בכל שכבה?
בהנחה שקבענו את גודל המדגם הכולל (ולא את גודל המדגם לכל שכבה בנפרד), יש מספר דרכים לקבוע איך לחלק אותו בין השכבות.
האפשרות הנאיבית היא לחלק את המדגמים באופן פרופורציונלי לגדלי השכבות. בדוגמה שלנו היה מדגם בגודל 1750. חלוקה פרופורציונלית בעיר שלנו הייתה מובילה למדגם בגודל 175 באיזור הצפון (10% מ-1750), 525 במרכז (30% מתוך 1750) ו-1050 בדרום (60% מתוך 1750).
מה נאיבי בחלוקה כזו? היא לא מתחשבת בשונויות שבתוך השכבות, ומכיוון שכך, למה לטרוח? כל הרעיון של מדגם שכבות הוא לנצל את ההבדלים שבין השכבות.
החלוקה האופטימלית מתבצעת על פי השונויות – ככל שהשונות בשכבה גדולה יותר, כך יידגמו יותר פרטים מהשכבה. בדוגמה שלנו נלקח מדגם בגודל 1000 ממרכז העיר בו מתגוררים 15000 תושבים, אך מדרום העיר שם מתגורר מספר כפול של תושבים נלקח מדגם קטן פי 4. זאת ככל הנראה מכיוון שהשונות בדרום העיר קטנה באופן משמעותי מהשונות במרכז העיר ((בהנחה כי גדלי המדגם האלה אכן חושבו על פי השונויות בכל שכבה אפשר לחשב פי כמה השונות בדרום העיר יותר קטנה מהשונות במרכז אם ממש רוצים))
דוגמה: למה בוטל המשחק של ארגנטינה בישראל
מה הסיבה המדוייקת לביטול אי אפשר כנראה לדעת, אבל אפשר לשאול את הציבור מה דעתו בנושא. הנה לדוגמה תוצאות של סקר שנערך בערוץ 10:

הסקר בוצע בצורת מדגם של שתי שכבות: האוכלוסייה היהודית ו-"המגזר הלא יהודי". טעות הדגימה לא דווחה. ((עוד שאלה מעניינת: כיצד מבצעים מדגם כזה בקרב אוכלוסייה מסויימת, יהודית או לא יהודית? למיטב ידיעתי, אלה סקרים טלפוניים, כאשר מספרי הטלפון אליהם מתקשרים נבחרים באופן אקראי. האם אפשר לדעת על פי מספר הטלפון האם האדם אליו מתקשרים הוא יהודי או לא יהודי? אני חושב שלא. ))
מהאוכלוסייה היהודית נלקח מדגם בגודל 615 ובמגזר הלא יהודי נלקח מדגם בגודל 150. מדוע נקבעה החלוקה הזו? יכולות להיות לכך מספר סיבות.
סיבה אפשרית אחת היא כי חישבו תחילה שגודל המדגם הכולל צריך להיות 765 ואחר כך חילקו אותו באופן קרוב לפרופורציונלי. זו לא חלוקה מדוייקת כי האוכלוסייה היהודית הבוגרת מהווה 76% מסך האוכלוסייה הבוגרת במדינה, על פי נתוני הלמ"ס לשנת 2015 (קישור לקובץ פדף). חלוקה פרופורציונלית צריכה להוביל למדגם בגודל 581 באוכלוסייה היהודית, ו-184 במגזר הלא יהודי. במקרה הזה, גודל המדגם במגזר הלא יהודי נמוך בכמעט 20% ממה שהוא צריך להיות על פי הקצאה פרופורציונלית.
סיבה אפשרית שניה היא כי ההקצאה נובעת מכך שהשונות בתוך המגזר הלא יהודי נמוכה באופן משמעותי מהשונות במגזר היהודי, ולכן גודל המדגם יכול להיות קטן יותר. ערכתי את החישובים ((למעוניינים ראו את הנוסחה כאן, תחת הכותרת Neyman Allocation)) ומצאתי כי אם זו אכן הייתה הסיבה, הרי שההערכה הייתה כי השונות במגזר הלא יהודי קטנה בערך ב-40% מהשונות באוכלוסייה היהודית. שאלה מעניינת היא על מה התבססה הערכה זו, אם אכן כך היה. במקרה הזה טעות הדגימה המירבית היא 3.4% ((בהנחה שבאוכלוסייה היהודית השונות לשאלת כן/לא היא מקסימלית ולכן שווה ל-0.25, ומכאן שהשונות המקסימלית במגזר הלא יהודי היא לכן 0.15)) . לו היו לוקחים מדגם רגיל בגודל 765 מתוך כל האוכלוסייה, טעות הדגימה המירבית הייתה 3.6%. כלומר, דגימת השכבות הפחיתה את טעות הדגימה ב-0.2%. ((למי שמעוניין לבדוק את החישובים שלי – מצורף קישור לקובץ pdf ))
סיבה אפשרית שלישית היא שלקחו את גודל המדגם "הרגיל" בו נהגו להשתמש כאשר ביצעו מדגמים רק בקרב האוכלוסייה היהודית – משהו בסביבות 500-600 ((שנותן טעות דגימה של 4 עד 5 אחוז)), והוסיפו מדגם יותר קטן במגזר הלא יהודי כדי לצאת ידי חובה.
המסקנה שלי מכל הדיון הזה היא שהאופן בו מתבצעים היום סקרי דעת הקהל – שני מדגמים, אחד בקרב האוכלוסייה היהודית ואחד במגזר הלא יהודי, אינו מביא תועלת רבה, ומתבסס על הנחה בעייתית במקרה הטוב: ההנחה כי שונות הדיעות בקרב המגזר הלא יהודי נמוכה באופן משמעותי מהשונות באוכלוסייה היהודית. כפי שראינו, גם אם הנחה זו נכונה, ההשפעה שלה על טעות הדגימה המירבית היא מזערית. במצב כזה ראוי יותר לבצע מדגם אחד שיכלול בתוכו את כל האוכלוסייה, יהודים ולא יהודים.
לקריאה נוספת
נשלח: 25 ביוני, 2018. נושאים: מה אומרת הסטטיסטיקה, סקרים.
תגובות: 5
| טראקבק
איך אפשר לדעת מי תזכה במונדיאל?
לכאורה, אין דבר יותר פשוט מזה. חפשו בגוגל "מי תזכה במונדיאל", ותקבלו המון תחזיות: תוכלו לדעת מה הייתה התוצאה של סימולציה שאיזה סטארט-אפ עשה, מה קבעו המומחים הפיננסיים, מה החליטו הקוראים של הארץ, והכי חשוב, מה חושבים נהגי המוניות:

הבעיה העיקרית היא שהדרך הכי טובה לדעת מה יקרה במונדיאל כבר לא קיימת. פול התמנון, עליו השלום, כבר לא איתנו. אני מקווה שנשמתו צרורה בצרור החיים.
אבל יש מי שמנסה למצוא יורש לפול. האתר psychic-pets.com קרא לעזרתם של בעלי חיות מחמד מכל העולם ומבקש מהם לנסות לברר מה יקרה. נכון למועד כתיבת שורות אלו, קרוב לאלף חיות מחמד נרתמו למשימה, מתוכן 85 חיות מחמד מגרמניה ושתיים מאירן. גם חיית המחמד שלי נמצאת שם. זהו ברווז, כמובן. לא סתם ברווז אלא ברווז פלא, העונה לשם Coin.
אז מה הסיכוי שהחיות האלה, או אפילו רק אחת מהן, יחזו את תוצאות המונדיאל? בואו נשתעשע במספרים. ((את החישובים ביצעתי בערת תוכנת R ))
קודם כל, למען הפשטות אני מוציא (בינתיים) מהמשחק את שלב הבתים, ומתרכז בשלב שאחריו, בו 16 נבחרות מתחרות בשיטת הנוק אאוט. יש בשלב הזה 15 משחקים משמעותיים (ועוד משחק אחד על המקום השלישי שהוא פחות מעניין). דרך אגב, כמה משחקים היו נערכים בשיטת הנוק אאוט אם לשלב הזה היו מגיעות לא 16 אלא 53 נבחרות? תחשבו על זה.
אז החיות שלנו צריכות לחזות את התוצאות של 15 משחקים. אני אשחק כאן את תפקיד פרקליטו של השטן ואטען שהחיות לא חוזות את התוצאות אלא מנחשות. אם כך, מה הסיכוי שחיה אחת תחזה את כל התוצאות של כל 15 המשחקים? לכל משחק יש שתי תוצאות אפשריות (אין תיקו). הסיכוי לניחוש נכון הוא לכן 50% או חצי. יש 15 משחקים, והם לא תלויים זה בזה (בדרך כלל): התוצאה של משחק קודם בדרך כלל לא משפיעה על התוצאה של המשחק הבא. אני יודע שההנחה הזו לא נכונה ב-100%. יכול להיות שנבחרת שהתאמצה מאוד במשחק מסויים תגיע יותר עייפה ומוחלשת לשלב הבא, יכול להיות ששחקן מפתח הורחק או נפצע, ועוד. אבל אם חיות המחמד מנחשות, הן לא לוקחות את כל הדברים האלה בחשבון, והניחושים שלהן לא תלויים זה בזה. לכן, ההסתברות לניחוש התוצאות של 15 משחקים היא ההסתברות לניחוש נכון של משחק אחד מוכפלת בעצמה 15 פעמים. זה יוצא 1 ל-32768, או 0.003%. סיכוי נמוך? בהחלט, אבל בכל זאת גדול מאפס.
אבל יש לנו קרוב ל-1000 חיות שמנסות לבצע את אותו התרגיל. אולי אחת מהן תצליח? כאן אפשר להשתמש בהתפלגות פואסון כדי לחשב את ההסתברות שאף חיה לא תצליח לחזות את כל התוצאות של כל המשחקים, שחיה אחת תצליח, ששתיים יצליחו וכולי. ובכן, ההסתברות שאף חיה מתוך האלף לא תצליח לחזות את התוצאות של כל 15 המשחקים היא 96.99%, ויש הסתברות של 2.96% שחיה אחת מבין האלף תצליח במשימה (אבל לא ניתן לדעת מראש איזה).
מצד שני, אני מטיל על החיות משימה לא הוגנת. בנדיק החתול מאיסלנד לא מתעניין בתוצאת המשחק שבין הונגריה ומיקרונזיה (אם יש בכלל משחק כזה). גם פול התמנון התמחה בנבחרת שלו, גרמניה. אז בואו נתרכז במשחקים של גרמניה.
אני מניח שגרמניה תשחק בסך הכל 7 משחקים – 3 בשלב המוקדם, ועוד ארבעה בשלב הנוק אאוט (כלומר, אני מניח שתגיע לחצי הגמר). לכן המשימה של מוקמוק הארנב ושאר חבריו מגרמניה אמורה יותר קלה – בואו נראה עד כמה היא יותר קלה.
שוב, לכל משחק יש שתי תוצאות: או שגרמניה מנצחת, וזה מה שחשוב, או שלא (ואני אתעלם כאן באלגנטיות ממה שלגארי לינקר היה לומר בעניין).
הסיכוי לניחוש נכון הוא חצי, ולכן הסיכוי לסדרה של שבעה ניחושים נכונים הוא חצי מוכפל בעצמו שבע פעמים. זה יוצא 1 ל-128, או 0.78%. עדיין נמוך, ועם זאת אפשרי.
אבל רגע. יש לנו 85 חיות מחמד מגרמניה. מה הסיכוי שלפחות אחת מהן תצליח? אנו נגייס שוב את התפלגות פואסון לעזרתנו. החישוב מראה לנו כי ההסתברות שאף אחת מבין 85 חיות המחמד לא תנחש את התוצאות של כל שבעת המשחקים היא כמעט 51.5%, ומכאן שיש הסתברות של 48.5% שלפחות אחת מהן תצליח במשימה. תיראו מופתעים.
אפשר כמובן לרדת לפרטים יותר קטנים: מה ההסתברות שלפחות חיה אחת תצליח לחזות תוצאה של שישה משחקים לפחות משבעת המשחקים של גרמניה (יותר מ-48.5%) או שלפחות חיה אחת תצליח לחזות את כל התוצאות של המשחקים של גרמניה בשלב הנוק אאוט בלבד (הרבה יותר מ-48.5%). לא ערכתי את החישובים האלה. אתם מוזמנים לנסות.
ועכשיו ברצינות. משחקי הניחושים האלה הם משעשעים ובדרך כל לא מזיקים. אולם יש אנשים שמהמרים על תוצאות המשחקים האלה. במקרה כזה לשאול את דג הזהב שלך מה תהיה התוצאה לדעתו זו לא אסטרטגיה טובה. אני מחזיר אתכם לחישובי הסטארט-אפ שהוזכר בפיסקה הראשונה ולאמירתו הבלתי נשכחת של גארי לינקר: "כדורגל משחקים תשעים דקות ובסוף גרמניה מנצחת". ב-2014, למשל, גרמניה ניצחה ב-6 משחקים מתוך השבעה ששיחקה (משחק אחד הסתיים בתיקו). הסטארט-אפ הנ"ל הכניס למודל שלו את תוצאות כל המשחקים שנערכו מאז 1930. אני אמנע מלהביע את דעתי כי אני לא מכיר את כל פרטי המודל.
אני הסתכלתי על התוצאות של נבחרת גרמניה בארבעת הטורנירים האחרונים: מ-2002 עד 2014. בתקופה הזו גרמניה ניצחה ב-9 משחקים מתוך 12 בשלב הבתים – 75% הצלחה. בשלבי הנוק אאוט גרמניה ניצחה ב-13 משחקים מתוך 16 (כולל שני משחקים על המקום השלישי) – 81% הצלחה.
לכן, בשלב הבתים ברווז הפלא שלי יטיל מטבע שנופל על עץ בהסתברות 75% ועל פלי בהסתברות 25%. יש לו סיכוי של קצת יותר מ-42% לנחש את התוצאות של שלושת המשחקים, פי 3.4 מסיכויי הניחוש של חיית מחמד אחרת שלא יודעת סטטיסטיקה. בשלב הבתים הברווז שלי יטיל מטבע שנופלת על עץ בהסתברות של 80%, ויהיה לו סיכוי של כמעט 41% לחזות את התוצאות של כל המשחקים, סיכוי גבוה פי 6.6 מהסיכוי של מוקמוק הארנב. הברווז שלי יכול לעשות הרבה יותר טוב מזה: הוא יכול "לנחש" תמיד שגרמניה תנצח: כך הסיכוי שלו לנחש נכונה את תוצאות כל המשחקים יהיה מעל ל-75%.
לפני שאתם רצים להמר אל תשכחו שסוכנויות ההימורים מכירות אל כל החישובים האלה (וגם חישובים יותר מסובכים) ולכן קובעות את שערי ההימורים כך שבסופו של דבר הן ירוויחו.
אני, אגב, לא צופה במשחקים, אבל מאחל שעות של הנאה למי שכן.
נשלח: 16 ביוני, 2018. נושאים: אותי זה מצחיק, הממ... מעניין..., חשבון פשוט, מה אומרת הסטטיסטיקה, ספורט.
תגובות: 5
| טראקבק
איך יודעים כמה אנשים מתים מנזקי העישון
מחדליו של סגן שר הבריאות בנושא המלחמה בעישון, תוארו בדו"ח של מבקר המדינה מחודש מאי 2018. בין היתר נאמר כי בכל שנה מתים בישראל כ-8,000 בני אדם כתוצאה ממחלות הנגרמות מעישון. יש לי הרבה מה לומר על אוזלת היד וחוסר המעש של מקבלי ההחלטות בנושא, אבל כאן אני מדבר בעיקר על סטטיסטיקה, והנושא שיעלה היום לדיון הוא הנתון בדבר המוות של 8000 בני אדם בשנה כתוצאה מעישון. איך יודעים את זה?
זהו כמובן אומדן שמתבסס על איסוף נתונים ויישום של שיטות סטטיסטיות. גם זה, כמו הרבה דברים אחרים, מתחלק לשלושה חלקים. החלק הקשה הוא החלק שבו אוספים את הנתונים. החלק הקל הוא החלק שבו מחשבים את החישובים (מזינים את הנתונים למחשב ולוחצים על הכפתור). וביניהם יש את החלק בו צריכים להבין מה עושים, ובאופן עקרוני זה לא מסובך.
כמה אנשים מתים?
נתחיל באיסוף הנתונים. נתון אחד שצריך לדעת הוא כמה אנשים מתים בכל שנה. זה לא קשה, לפחות במדינה מסודרת שבה נאספים נתונים כאלה באופן מסודר וקבוע. נתוני תמותה נאספים בדרך כלל במשך שנים רבות. הלשכה המרכזית לסטטיסטיקה מפרסמת בכל חמש שנים לוחות תמותה המבוססים על הנתונים שנאספו בחמש השנים שקדמו לשנת הפרסום. מייד נעיין באחד הלוחות (קישור לקובץ pdf). הנה קטע מלוחות התמותה של הלשכה המרכזית לסטטיסטיקה, המתייחס לגברים יהודים ואחרים (כלומר – לא ערבים), בין השנים 2011 ל-2015:

אני יודע שהסיכוי שלי למות בסופו של דבר הוא 100%. אבל אני בעזרת לוח התמותה יכול לדעת יותר מזה. אני גבר יהודי בן 55, ומהשורה האחרונה של לוח התמותה שבתמונה אני יכול ללמוד כי בהיעדר כל מידע נוסף, הסיכוי כי אמות בשנה הקרובה הוא 0.00425. לחילופין, על פי נתוני הלשכה, מתוך כל 100000 גברים יהודים, 95506 יגיעו לגיל 56, ו-4494 לא יזכו לכך. אני יודע שיש חוסר תיאום בין שני המספרים האלה, וזה נובע מתוך דקויות סטטיסטיות שלא אכנס אליהן כאן ((אתם מוזמנים לקרוא את דברי ההסבר בקובץ לוחות התמותה)). אני גם יכול ללמוד מהלוח כי תוחלת החיים שלי, בהינתן שכבר הגעתי לגילי המופלג, היא 27.6 שנים פלוס מינוס סטיית תקן ואירועים לא צפויים. יש גם סיכוי שאגיע לגיל 100, אך הוא קטן למדי.
לעומת זאת, לגבר ערבי בגיל 55 במדינת ישראל, הסיכוי למות לפני גיל 56 יותר גבוה: 0.00595, ותוחלת החיים שלו נמוכה יותר: נותרו לו, בממוצע, רק עוד 24.9 שנים לחיות.
איזה נתונים צריך כדי לאמוד את סיכוני העישון?
הנתון השני צריך לאפשר לנו לאמוד כמה אנשים מתו מנזקי עישון. זה כבר יותר מסובך. כולם מתים בסוף, גם אלה שמעשנים וגם אלה שלא. אדם יכול לעשן ולמות מסיבה שלא קשורה לעישון (אולי ממחלה זיהומית, אולי מתאונה, ואולי אפילו מסרטן שעישון אינו גורם סיכון שלו – יש סרטנים כאלה). אדם יכול לא לעשן ובכל זאת למות מסרטן הריאות או מחלת לב – כאשר עישון הוא גורם סיכון ידוע לשני המצבים הבריאותיים האלה. (( נשאלת כמובן השאלה איך יודעים שאלה גורמי סיכון, והתשובה תתברר מייד )) ובכל זאת, הנתונים שיש לאסוף הם כמה אנשים מתים, כמה מהם מעשנים, וכמה לא.
במקומות רבים בעולם נערכים מחקרים תצפיתיים ארוכי טווח העוקבים אחרי מהלך החיים של אוכלוסיות, ואוספים נתונים על התנהגויות העשויות להשפיע על מצב הבריאות של הפרטים באוכלוסייה, כגון הרגלי אכילה ועישון. המחקר הידוע ביותר נערך בעיר פראמינגהם במדינת מסצ'וסטס בארצות הברית. החל משנת 1948 נאספים נתונים כאלה על אלפים מתושבי העיר שהסכימו להשתתף במחקר, והוא עוקב כעת אחרי הדור השלישי של התושבים. באתר המחקר תוכלו למצוא מחשבונים שבעזרתם תוכלו לדעת מה הסיכון שלכם ללקות במחלת לב. המחקר הזה הראה כי עישון הוא גורם סיכון משמעותי לסיכוי לחלות במחלת לב.
מחקר אחר, קצת ישן (משנת 1999) שערכו יעקובס ועמיתיו, עקב אחרי אוכלוסייה של כ-12000 איש בשבע מדינות במשך 25 שנים. המחקר אסף נתוני תמותה מכל סיבה שהיא, וכמובן נתונים נוספים. אחת המסקנות של המחקר הזה הייתה כי הסיכון למות של מעשנים המעשנים עד 10 סיגריות ביום גבוה פי 1.3 מהסיכון של לא מעשנים, והסיכון למות של אלה המעשנים יותר מ-10 סיגריות ליום גבוה פי 1.8 מאלה של הלא מעשנים. ללא הסבר המספרים האלה נראים תמוהים. מה זאת אומרת שהסיכון למות גבוה פי 1.8? כולם מתים בסוף. הסיכון למות הוא 100% לכולם. לא? לא. הסיכוי שאדם ימות בסופו של דבר הוא אכן 100%. הסיכון הוא לא סיכוי. אז בואו נעשה סדר.
איך מודדים את הסיכון
הסיכון נגזר מהסיכוי למות (או לחוות אירוע אחר כלשהו, כמו התקף לב למשל) במשך יחידת זמן מוגדרת, ומתייחס לנקודה ספציפית בזמן (או לתקופת זמן קצרה מאוד). אל תיבהלו, אבל אני אומר לכם שהסיכון הוא הנגזרת של ההסתברות המותנה למות (אתם יכולים לעבור הלאה בלי חשש). הסיכוי, לעומת זאת, מתייחס לתקופות זמן ארוכות יותר.
אני לא אכנס כאן להגדרה המתמטית המדוייקת של הסיכון. אומר רק שאם יודעים את הסיכוי למות במשך תקופת מסויימת, נניח שנה, אפשר לחשב מכך את הסיכון למות במשך אותה תקופת זמן. גם ההיפך נכון: אם יודעים את הסיכון אז יודעים את הסיכוי. כמו כן, באופן לא מפתיע, אם הסיכוי שלך למות בשנה הקרובה גבוה יותר, אז גם הסיכון שלך גבוה יותר.
ואם אפשר לעשות את האבחנה הזו בין יהודים וערבים, ובין גברים לנשים, בוודאי שאפשר לחשב את הסיכון של המעשנים ולהשוות אותו לסיכון של הלא מעשנים.
הכלי הסטטיסטי שמאפשר לבצע את התרגילים האלה הוא מודל הסיכונים הפרופורציונליים שפותח בשנת 1972 על ידי הסטטיסטיקאי הבריטי סיר דויד קוקס, וידוע גם בשם מודל קוקס. קשה להמעיט בחשיבות של המודל הזה. המאמר שבו הוצג המודל נמנה עם 100 המאמרים המדעיים המצוטטים ביותר בכל הזמנים – לא מאמרים בסטטיסטיקה, אלא כל המאמרים המדעיים. המודל מאפשר לזהות גורמי סיכון להתרחשות אירועים כגון מוות, ולמדוד מה פוטנציאל הסכנה בכל גורם סיכון כזה. בנוסף לכך, קוקס הציג במאמר שלו חידושים סטטיסטיים נוספים שהשפיעו רבות גם על תחומים אחרים בסטטיסטיקה. אילו היה פרס נובל לסטטיסטיקה, סיר דויד קוקס היה זוכה בו ללא צל של ספק. סיר קוקס אכן זכה כמעט בכל פרס אפשרי בתחום הסטטיסטיקה. המודל שלו בפירוש מאפשר הצלת חיים. לדעתי סיר קוקס ראוי לזכייה בפרס נובל לרפואה.
להלן נוסחת המודל. מייד אסביר הכל. ניתן לראות כי זהו למעשה מודל רגרסיה.
![]()
נתחיל בצד שמאל. שם מופיע הסיכון כפי שהוא מושפע מגורמי הסיכון – אותו אנחנו רוצים לאמוד. הוא מסומן באות למבדה – האות היוונית שדומה לאות ג. בצד ימין יש מכפלה של שני חלקים. חלק אחד מתאר את הסיכון הבסיסי – כאשר אין שום אינפורמציה. הוא מסומן בלמבדה אפס טי. הסיכון הבסיסי נקבע רק על פי נתוני התמותה. לכל אדם במדגם נתון האם הוא מת, אם כן, מתי, ואם לא, כמה שנים הוא חי עד למועד שבו הוחלט להפסיק את המעקב ולהזין את הנתונים למודל. החלק השני מכיל את גורמי הסיכון האפשריים, כגון גיל, מין, הרגלי אכילה, וגם כמובן משתנה המציין האם האדם שבמדגם מעשן או לא. גורמי הסיכון מסומנים באיקסים. לכל X יש מקדם שמסומן באות ביתא. אם ביתא שונה באופן משמעותי מאפס זה אומר שלמשתנה X יש השפעה משמעותית על הסיכון. אם ביתא חיובי זה אומר שהסיכון גדל ככל ש-X גדל, ואם ביתא שלילי זה אומר של-X יש דווקא השפעה חיובית. רמת הסיכון עולה (או יורדת) באופן פרופורציוני לערכו של .X (( באופן יותר מדוייק: ההשפעה היא פרופורציונית לגבי הלוג של יחס הסיכונים )) מכאן נובע שם המודל – מודל הסיכונים הפרופורציוניים. לאחר שאומדים את הפרמטרים של המודל אפשר, באופן תיאורטי, לחשב את הסיכון לאדם מעשן ולאדם לא מעשן. (( את זה עושים על ידי כך שקובעים ש-X הוא משתנה שמקבל שני ערכים: 0 אם האדם לא מעשן, 1 אם הוא כן מעשן. כאשר X שווה ל-1 נוסף הערך ביתא לסכום המשוקלל של גורמי הסיכון )) בפועל, המודל מספק ישירות אומדן ליחס שבין הסיכונים, ה-hazard ratio. היחס הזה מתבטא במקדם הביתא של משתנה העישון.
למודל יש כמובן גם הנחות. החשובה שביניהן היא ההנחה כי יחס הסיכונים נשאר קבוע לאורך כל תקופת המעקב. זו הנחה חזקה, ובדרך כלל היא נכונה, וגם אם יש סטייה לא גדולה מההנחה הזו המודל מספיק עמיד (robust) כדי לספק אומדן טוב של הסיכון. יש הרחבות למודל שבהן מחליפים את ההנחה הזו בהנחה יותר גמישה אם יש צורך. אחד המודלים הידועים שמרחיבים את מודל קוקס פותח על יד שילה בירד.
איך מתרגמים את הנתונים למספרים
עכשיו נוכל לעשות את החישובים.
יש לנו את ההסתברויות למות בכל גיל מלוחות התמותה. יש לנו את גם יחס הסיכונים שהוא כזכור היחס בין הסיכון למות של אנשים המעשנים יותר מ-10 סיגריות ביום ובין הסיכון של לא מעשנים. זכרו כי זהו יחס הסיכונים לנקודה ספציפית בזמן. מתוך יחס הסיכונים אפשר לחשב את יחס הסיכויים: היחס בין ההסתברויות למות במשך תקופת זמן מוגדרת, שנה למשל. בשביל זה יש נוסחה. אני אחסוך לכם אותה. יש בה אינטגרלים ואקספוננטים, וזה בדרך כלל לא טוב לבריאות. אם אתם ממש רוצים אז אתם יכולים לקרוא כאן, למשל, אבל זה על אחריותכם (קישור לקובץ pdf). אני חוסך את זה גם לעצמי, ואשתמש בנתון מתוך מאמר אחר מאת מהטה ופרסטון משנת 2012. לפי הנתונים במאמר הזה, יחס הסיכויים למוות בתקופת זמן של שנה, בין גברים מעשנים וגברים לא מעשנים הוא בערך 2.3 (לקחתי את הגבול התחתון של רווח הסמך, כדי לקבל הערכה שמרנית), לאחר תקנון לגיל, וזאת בארצות הברית, בשנים 1987 עד 2006.
אנחנו צריכים עוד נתון אחד והוא שיעור המעשנים באוכלוסייה. לצורך הדוגמה אשתמש בנתונים של משרד הבריאות משנת 2017, לפיהם כ-30% מהגברים מעל גיל 21 הינם מעשנים..
כשיש לנו את כל הנתונים מה שנשאר זה קצת אלגברה של בית ספר תיכון. (( אני יודע שאני עושה פה סלט: נתונים מארצות הברית מסוף המאה העשרים ותחילת המאה העשרים ואחת, ונתונים מישראל. הכל נעשה לצורך הדגמה. אל תסיקו מסקנות מהמספרים שתראו בהמשך. ))
נניח שהסיכוי של מעשן בן 55 למות לפני גיל 56 הוא X, והסיכוי של לא מעשן הוא Y. לפני הנתון של מהטה ופרסטון, X גדול פי 2.3 מ-Y, כלומר X=2.3Y. זה נותן לנו משוואה אחת המקשרת בין X ל-Y.
את המשוואה השנייה נגזור מתוך מה שידוע בשם נוסחת ההסתברות השלמה. ניתן להציג את החישוב בצורת עץ הסתברויות:
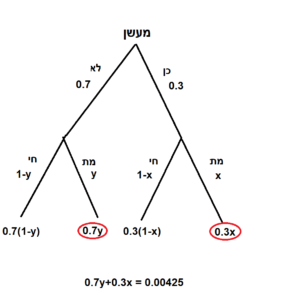
מהי ההסתברות של גבר בן 55 למות? ההסתברות הזו שווה להסתברות שלו למות אם הוא מעשן שהיא כאמור X כפול ההסתברות שהוא מעשן, שהיא 30%, ולכך יש להוסיף את ההסתברות שלו למות אם הוא לא מעשן, Y, כפול ההסתברות שהוא לא מעשן, שהיא 70%. כל זה צריך להיות שווה ל-0.00425, כלומר 0.3x+0.7y=0.00425.
עכשיו יש לנו שתי משוואות בשני נעלמים ואפשר לפתור אותן. הפתרון הוא ש-X, ההסתברות שגבר יהודי מעשן בן 55 ימות לפני שיגיע לגיל 56 – שווה ל-0.00703237, ואילו Y, ההסתברות שגבר יהודי בן 55 שאינו מעשן ימות לפני שיגיע לגיל 56 היא הרבה יותר נמוכה: 0.00305755.
כזכור, על פי לוח התמותה, ההסתברות שגבר בן 55 ימות לפני שיגיע לגיל 56 היא 0.00425. זה אומר שאם יש לנו 100000 גברים כאלה, אז בממוצע ימותו במהלך השנה 425 מהם. אם לעישון אין השפעה על ההסתברות למות, אז 30% מהמתים יהיו מעשנים: בערך 128 איש.
אבל אנחנו יודעים שההסתברות למות שונה למעשנים ולא מעשנים.
בין 100000 הגברים יש 30000 מעשנים, ולכל אחד מהם הסתברות למות השווה כאמור ל- 0.00703237. זה אומר שמתוכם ימותו 210 איש – 82 איש יותר ממה שהיה צריך להיות אילו לעישון לא הייתה השפעה. 82 האנשים האלה מתו לכן בגלל שהיו מעשנים.
כך אפשר לערוך את החישוב לכל מין, לכל גיל, ולכל קבוצת אוכלוסייה למעשה. אם עושים את החשבון עם כל הנתונים המדוייקים (שלא היו בידיי), אז מגיעים ל-8000 מחברים את תוצאות כל החישובים ומגיעים למספר הכולל.
מה בקשר לעישון פאסיבי
העקרון הוא אותו עיקרון, אם כי היישום יותר מסובך. אני חייב להודות שאני לא יודע באיזה שיטה משתמשים כדי לאמוד את מספר הנפגעים מעישון פאסיבי.
בגדול יש שתי אפשרויות: להגדיר באופן כלשהו משתנה המציין אם אדם נחשף לעישון פאסיבי או לא נחשף, ואז החישוב הוא כפי שנעשה קודם. אפשרות שניה היא להגדיר את רמת החשיפה לעישון פאסיבי כמשתנה כמותי ואז יחס הסיכונים פרופורציונאלי לרמת החשיפה. ברמה העקרונית החישוב נשאר אותו חישוב, אלא שכאן מדובר במשתנה רציף ולכן הפירוק להסתברויות לפי רמת החשיפה מסובך יותר.
כמה מילים בנימה אישית
וכאן אני רוצה לומר כמה מילים אישיות.
עדכון פברואר 2026: לצערי, אחי שעישן עד גיל 40 והפסיק לעשן כמתנת יום הולדת לגיל זה, נפטר לפני כחודשיים (בדצמבר 2025) לאחר שחלה בסרטן הריאה, כ-3 שבועות לפני יום הולדתו ה-60.
זאת למרות הנתונים שמראים כי למי שמפסיק לעשן עד גיל 40 סיכויי ההישרדות גבוהים באופן משמעותי בהשוואה למי שלא הפסיק. זה מה שנקרא "ליפול בצד הלא נכון של הסטטיסטיקה". המסר האישי שלי: במקום להפסיק לעשן – פשוט אל תתחילו.
אני חושב שהנתון כי בכל שנה מתים בישראל 8000 איש מנזקי עישון הוא מזעזע. אם מחר תפרוץ חלילה מלחמה וימותו בה 8000 איש העם יצא לרחובות. אם השנה ייהרגו 8000 איש בתאונות דרכים, שר התחבורה והשר לביטחון פנים לא יוכלו להתחמק מאחריות. 8000 מתים בשנה פירושם יותר מ-20 מתים כל יום. אם חלילה יתרחש פיגוע וייהרגו בו 20 איש, אף אחד לא יחכה שהמספר יצטבר ל-8000 לפני שיידרשו לעשות משהו, ובצדק.
כמו שאמר סטאלין, מוות אחד הוא טרגדיה אבל 8000 מתים הם כנראה רק סטטיסטיקה. לסטטיסטיקה הזו אחראים המנהיגים שלנו ומקבלי ההחלטות. בשנת 2011 הוכרזה תכנית לאומית למלחמה בעישון ובנזקיו. בפועל לא קרה כמעט כלום. הגיע הזמן לתכנית חדשה, והפעם זו צריכה להיות תכנית חירום לאומית למלחמה בעישון. עכשיו.
עוד עדכון 2026: מאז 2018 אוכלוסיית ישראל גדלה ב-13.5%. תכנית לאומית למלחמה בעישון ונזקיו – אולי יש, אני בכל מקרה לא ראיתי שום דבר. יש לנו עכשיו עניינים חשובים יותר לעסוק בהם: איראן, קטאר, חוק השתמטות, בתי משפט, חנינות ועוד. נראה כי כל דבר יותר חשוב ממניעת מותם של 9100 אנשים בשנה.
נשלח: 19 במאי, 2018. נושאים: ביוסטטיסטיקה, בריאות, האנשים שמאחורי הסטטיסטיקה, מה אומרת הסטטיסטיקה, ניהול סיכונים.
תגובות: 10
| טראקבק
איך לא לתפוס רוצח בעזרת התאמת DNA
לקראת סוף אפריל 2018 דווח כי משטרת סקרמנטו בקליפורניה עצרה אדם החשוד כי הוא ה-Golden State Killer, רוצח סידרתי שפעל באיזור בשנות ה-70 וה-80 של המאה העשרים. החשוד זוהה בעקבות התאמה של דגימות DNA שנלקחו בזמן חקירות מעשי הרצח ונתוני DNA שפורסמו באתר של אחת החברות המציעות לקהל הרחב ניתוח בסיסי של ה-DNA שלהם. כיצד מתבצעת ההתאמה ומה המשמעות של התוצאות? מכיוון שלא נמסרו נתונים לגבי תהליך הזיהוי במקרה זה, אסביר את הנושא בעזרת מקרה אחר, בעזרתו אדגים את תפקידה של הסטטיסטיקה בתהליך.
רצח דיאנה סילבסטר
דיאנה סילבסטר, אחות במקצועה, נרצחה בדירתה בסן פרנציסקו מספר ימים לפני חג המולד ב-1972, לאחר שנאנסה באכזריות. אישה ששהתה בדירה אחרת בבניין שמעה צעקות, ולאחר המתנה של כעשרים דקות החליטה לצאת מדירתה ולבדוק מה קורה. היא ראתה כי דלת דירתה של סילבסטר פתוחה, ואדם שעמד בפתח הדירה. לשאלתה ענה לה כי "אנחנו עושים אהבה", ולאחר מכן הלך לדרכו. האישה נכנסה לדירה ושם מצאה את גופתה העירומה של סילבסטר. המשטרה הוזעקה, האישה מסרה את עדותה כולל תיאורו של האדם שראתה. מגופתה של דיאנה נלקחו דגימות זרע, בין היתר. לאחר מספר ימים עצרה המשטרה אדם חסר בית שתיאורו התאים לתיאור שמסרה העדה כחשוד ברצח. המשטרה לא הצליחה למצוא ראיות מספיקות נגד החשוד והוא שוחרר. חשוד זה, אגב, הורשע באונס מספר חודשים לאחר מכן. נבדקו עוד כעשרים חשודים נוספים, אך לא בוצעו מעצרים נוספים. תיק הרצח, ובתוכו דגימות הזרע, נגנז והועבר לארכיון.
בשנת 2003, לאחר שפותחה טכנולוגיה לניתוח והתאמה של דגימות DNA, בדקה משטרת סן פרנציסקו האם יש התאמות בין דגימות DNA שנאספו ונשמרו במקרי רצח לא פטורים ובין דגימות DNA במאגר של עברייני מין שהורשעו במדינת קליפורניה. אמנם ה-DNA שנאסף מגופתה של סילבסטר לא נשמר היטב, ומתוך 13 האללים המשמשים לזיהוי (פרטים בהמשך) ניתן היה לקבל אינפורמציה רק על 5.5 אללים, עם זאת, נמצא במאגר אדם עם DNA התואם את אותם 5.5 אללים. אדם זה, ג'ון פאקט, נעצר כחשוד ברצח, הועמד לדין והורשע.
איך מבצעים התאמת DNA?
ההסבר שאתן מאוד פשטני ולא מדוייק, אך הוא מספיק לצורך הדיון בבעיה הסטטיסטית. DNA הוא מולקולה, שרשרת של חלבונים, הנמצאת בכל תא בגוף. כל התכונות הביולוגיות של האדם נקבעות על ידו. ה-DNA מתחלק ליחידות שנקראות אללים. יותר מ-99.9% מה-DNA זהה אצל כל בני האדם. השונות בין בני אדם (נניח צבע עיניים) נקבעת על ידי שאר ה-DNA. למרות הזהות של99.9% מה-DNA בין כל בני אדם, אין למעשה שני אנשים עם DNA זהה לחלוטין, אלא אם הם תאומים זהים.
מבחינה משפטית ופלילית, זיהוי של אדם נקבע על ידי 13 אללים ספציפיים. כדי לבדוק האם שתי דגימות DNA נלקחו מאותו אדם, משווים את 13 האללים בין שתי הדגימות. אם אין התאמה אפילו באלל אחד מבין השלושה עשר – מדובר בשני אנשים שונים. מצד שני, אם הדגימות נלקחו משני אנשים שונים – הסיכוי כי תהיה התאמה מלאה בין כל 13 האללים נמוך מאוד. עד כמה נמוך? יש כל מיני הערכות לכך. לפי ה-FBI, ההסתברות לכך היא בערך 1 ל-13 מיליארד.
ההשוואה מתבצעת על ידי השוואת שני גרפים המתקבלים מעיבוד דגימת ה-DNA במכשיר ייחודי. הגרף דומה לגרף המתקבל מדגימת א.ק.ג. 13 האללים המדוברים מתבטאים בגרף כ-"פיקים". ההשוואה נעשית בדרך כלל "לפי העין" על ידי מומחים בתחום. ((אני מניח כי במשך הזמן פותחו שיטות יותר אובייקטיביות להשוואה או שלפחות נעשה מאמץ לפתח שיטות כאלה. )) לדוגמא אני מביא כאן גרפים של שתי דגימות DNA ממשפט אחר (( הגרפים נלקחו מהספר Math on Trial. ראו הפניות לקריאה נוספת בסוף הפוסט. )) מה דעתכם? האם יש זהות בין שתי הדגימות?

המומחים המטעם התביעה באותו משפט אמרו שכן. הטענה נדחתה על ידי השופט שטעה טעות סטטיסטית שאינה קשורה לניתוח ה-DNA עצמו.
אציין גם הקביעה שזיהוי אדם מתבסס של 13 האללים האלה מתבססת על הנחות ביולוגיות/גנטיות וכן על הנחות סטטיסטיות. לא אכנס כאן לדיון מפורט בעניין משתי סיבות: ראשית, אני לא ממש מתמצא בנושא, ושנית, במקרה של הנחות אחרות היה נקבע קריטריון זיהוי אחר, אבל הבעיה הסטטיסטית של הרשעה על ידי זיהוי DNA נשארת אותה בעיה.
משפט הרצח
במקרה הרצח של סילבסטר הייתה כאמור רק התאמה חלקית, בגלל תהליך ההתפרקות של דגימת הזרע במשך 30 השנים בהן הוא נשמר בארכיון. התובע במשפט ציין שההסתברות כי תהיה התאמה כזו בין שתי דגימות DNA שנלקחו משני בני אדם שונים נאמדה כ-1 ל-1.1 מיליון, ואני מניח כי נתון זה נכון. השופט החליט כי במשפט לא יובאו מומחים שידונו בפרשנות של ההסתברות שהתובע ציין להתאמת ה-DNA ובהשלכות הנובעות מכך, ובפרט לא הוצגו עדויות של סטטיסטיקאים מטעם ההגנה, וכפי שנראה מייד, היה להם מה לומר. כמו כן, הוא החליט כי לא המושבעים לא יקבלו מידע על הדרך בה אותר החשוד. הם הונחו לשקלל את הנתון על הסתברות ההתאמה עם עדויות "רגילות". עדת הראיה שראתה ככל הנראה את הרוצח כבר מתה. בפני המושבעים הוצגו, פרט לנתון של 1 ל-1.1 מיליון, תיאור של שלושת מקרי האונס בהם הורשע פאקט בעבר ותמונה ישנה של הנאשם משנות השבעים בה הוא נראה דומה לתיאור של הרוצח שמסרה העדה. במהלך הדיונים ביקשו המושבעים מהשופט כי יימסר להם עוד מידע לגבי האופן שבו הגיעו אל החשוד בעזרת דגימת ה-DNA, אך השופט סירב למסור אינפורמציה זו. הנאשם, כאמור, הורשע ברצח.
ניתוח סטטיסטי
הניתוח שאתאר כאן מתייחס רק לראיית ה-DNA, ואינו לוקח בחשבון ראיות אחרות. כדי לקבוע אשמה יש לשקלל, כפי שטען השופט בצדק, את הראיה הזו עם הראיות האחרות שהוצגו במשפט. אם זאת, אני טוען כי האופן בו הוצגה ראיית ה-DNA למושבעים היה מטעה, והשופט שגה בכך שלא הרשה לצדדים להציג את טיעוניהם, ולכן גרם לכך שהמושבעים יפרשו את הנתון הזה באופן שגוי.
טיעוני התביעה
המסר של התביעה בעניין התאמת ה-DNA היה פשוט: הסיכוי שתהיה התאמה בין שתי הדגימות הוא 1 ל-1.1 מיליון. לכן השתמע מדברי התובע כי הסיכוי שפאקט אינו הרוצח הוא 1 ל-1.1 מיליון. זה לא נכון. זוהי ההסתברות כי אם נבחר שני בני אדם באופן מקרי תהיה ביניהם התאמה באותם 5 וחצי אללים ספציפיים. זה נכון גם כאשר נשווה את ה-DNA שלי ל-DNA שלך.
ההסתברות שהתביעה צריכה להציג היא הסתברות מותנית: ההסתברות שהנאשם הוא הרוצח כאשר ידוע לנו כי קיימת התאמת DNA. זה נראה פשוט, אבל צריך להיזהר: בהחלט ייתכן כי הנאשם אינו הרוצח גם אם קיימת התאמת DNA. ייתכן כי יש אדם נוסף שקיימת בינו ובין דגימת ה-DNA התאמה, ואולי אפילו יותר מאחד, ואם כך, ייתכן כי האדם הנוסף הזה הוא הרוצח. וזה מה שההגנה התכוונה לטעון.
טיעוני ההגנה (שלא הוצגו למושבעים)
למעשה היו להגנה שני טיעונים עיקריים. ראשית הם טענו כי יש עדויות אמפיריות וחישוביות לכך שהתאמת DNA חלקית נפוצה למדי. הם הסתמכו על מחקר שנערך באריזונה. חוקרת בשם קתרין טרויר בדקה כ-65,000 דגימות DNA. היא מצאה 122 זוגות של דגימות בהם הייתה התאמה ב-9 אללים, ו-20 זוגות בהם הייתה התאמה של 10 אללים. ההסתברויות להתאמות כאלה הרבה יותר קטנות מ-1.1 מיליון. סביר להניח כי במדגם כזה יימצאו אפילו יותר זוגות תואמים ב-5.5 אללים.
קל לחשב את ההסתברות הזו. זוהי למעשה בעיית ימי ההולדת. הקוראים הוותיקים שלי יודעים כי אם בחדר אחד מתאספים 23 איש, ההסתברות כי יהיה בחדר זוג אנשים שחולקים יום הולדת משותף גדולה מ-50%. בבעיית התאמת ה-DNA, מוחלף יום ההולדת בפרופיל ה-DNA. בבעיית ימי ההולדת ההסתברות ששני בני אדם יחלקו יום הולדת היא 1 ל-365. כל מה שצריך זה להחליף את ההסתברות להתאמת ימי הולדת בהסתברות להתאמת DNA ולערוך את החשבון. ההסתברות היא כמעט 1. למעשה, ההסתברות כה קרובה ל-1 עד כדי כך שתכנת R בה השתמשתי לחישוב נתנה את התוצאה 1, מכיוון שרמת הדיוק המקסימלית שלה היא רק כ-300 ספרות לאחר הנקודה העשרונית. ה-DNA שנלקח מזירת הרצח נבדק מול מאגר DNA שהכיל כ-338000 דגימות של עברייני מין מורשעים, גברים לבנים, שהיו מבוגרים מספיק כדי לבצע את הרצח בשנת 1972. אפשר לומר בביטחון כמעט מוחלט שיש ביניהם שני אנשים שה-DNA שלהם תואם ב-5.5 אללים. אז לכאורה אפשר לומר שסביר מאוד כי תימצא התאמה בין ה-DNA של פאקט ובין הדגימה שנלקחה מזירת הרצח. אבל רק לכאורה, כי גם האמירה הזו אינה נכונה. אנחנו חישבנו את ההסתברות כי יימצא זוג אנשים כלשהו שביניהם יש התאמת DNA. השאלה הנכונה היא מה ההסתברות כי במאגר יימצא אדם שה-DNA שלו תואם ל-DNA שנלקח מזירת הרצח.
גם בשאלה הזו דנתי בפוסט על בעיית ימי ההולדת (( זוכרים מה קרה לג'וני קארסון? )), וההגנה ביקשה להציג את ההסתברות הזו בפני המושבעים. הטיעון שלהם השתמש באנלוגיה של הגרלה (כגון הגרלת מפעל הפיס). האנלוגיה לכרטיס הגרלה היא אדם כלשהו, וה-DNA מזירת הפשע הוא המספר הזוכה. אם אתה קונה כרטיס אחד להגרלה שבה יש 1.1 מיליון כרטיסים, הסיכוי כי תזכה הוא 1 ל-1.1 מיליון. אם אתה קונה שני כרטיסים, הסיכוי שלך לזכות הוא 2 ל-1.1 מיליון, וכן הלאה. המשטרה בדקה מאגר של 338000 דגימות. הם קנו 338000 כרטיסים. הסיכוי שלהם לזכות הוא לכן 338000 ל-1.1 מיליון, שזה בערך 0.31. ההגנה טענה לכן כי הסיכוי שיימצא במאגר מישהו שה-DNA שלו מתאים לדגימה הוא בערך 1 מתוך 3. פאקט החזיק למזלו (הרע) בכרטיס הזוכה. לכן, גם אם זכה, אין למהר להסיק כי הוא הרוצח. ייתכן והיו מוצאים מישהו אחר. הסיכוי שימצאו מישהו הוא 30%. יותר מכך: במטרופולין סן פרנציסקו גרים מעל 3 מיליון איש, כמחציתם גברים. גם אם ניקח בחשבון רק את הגברים הלבנים שהינם די מבוגרים כדי לבצע את הרצח 30 שנה קודם לכן, חייב להיות שם מישהו עם DNA תואם לדגימה (( או באופן יותר מדוייק: ההסתברות כי יש שם אדם כזה גבוהה )). אבל גם החישוב הזה לא מדוייק.
החישוב האחרון מניח כי לכל אדם במאגר יש DNA שונה מזה של כל האחרים. שוב, ההנחה הזו לא נכונה. למעשה ראינו כי ההסתברות שיש במאגר שני אנשים עם DNA תואם ב-5.5 אללים היא כמעט ודאית.
כמו כן, ייתכן כי יש במאגר 2, 3 או אפילו יותר אנשים עם DNA תואם לדגימה. זו לא בעיית מפעל הפיס. זו בעיית לוטו. ה-DNA של כל אדם הוא המספרים שבחר. בהגרלת לוטו ייתכן מאוד כי שני אנשים ייבחרו את אותם המספרים, ופעמים רבות הפרס הראשון מתחלק בין מספר זוכים. אותנו מעניינת ההסתברות כי יהיה לפחות זוכה אחד.
אפשר לחשוב על הבעיה גם באופן הבא: יש לכם מטבע שהסיכוי שלו ליפול על עץ הוא 1 ל-1.1 מיליון. אתם מטילים אותו 338000 פעמים. מה הסיכוי כי המטבע ייפול פעם אחת על עץ? מה הסיכוי כי הוא ייפול על עץ יותר מפעם אחת? מה הסיכוי כי הוא לא ייפול על עץ אפילו פעם אחת (כלומר 338000 פעמים תקבלו פלי)? אפשר לחשב את הסיכויים האלה על ידי שימוש בהתפלגות פואסון, או בניסוח יותר מדוייק, הקירוב הפואסוני להתפלגות הבינומית, כאשר הפרמטר של ההתפלגות הוא 0.31. כאשר עורכים את החישוב מקבלים כי ההסתברות שהמטבע ייפול על עץ בדיוק פעם אחת, כלומר יש בדיוק אדם אחד במאגר אשר ה-DNA שלו מתאים לדגימה מזירת הפשע, היא 0.226. ההסתברות כי במאגר לא יימצא אפילו אדם אחד עם DNA תואם היא 0.736, וההסתברות כי יש במאגר לפחות אדם אחד עם DNA תואם לדגימה מזירת הפשע היא לכן רק 0.265 ולא 0.31 כפי שההגנה רצתה לטעון. יותר קרוב ל-1 מתוך 4 מאשר ל-1 מתוך 3, אך עדיין הסתברות גבוהה למדי.
המשמעות של התוצאה הזו כי יש הסתברות של מעל 25% כי הנאשם זכאי בהינתן ההתאמה בין ה-DNA שלו ובין ה-DNA שנלקח מזירת הפשע, ולא 1 ל-1.1 מיליון, כמו שהתובע רצה שהמושבעים יחשבו. לדעתי החישוב הזה מספיק כדי לעורר ספק סביר.
גישה בייסיאנית
יש עוד דרך להסתכל על הבעיה. אני לא חסיד של הגישה הזו, אבל אציג אותה בכל זאת. הבעתי בהרחבה את דעתי על הגישה הזו בפוסט שעסק במה שכונתה "מכונת האמת המוחלטת".
הדיון עד כה נערך תחת ההנחה שהנאשם זכאי, כפי שמקובל במערכות משפט במדינות דמוקרטיות. ראינו כי תחת ההנחה הזו ההסתברות כי הנאשם אשם היא כ-74%. אבל, מה הסתברות שתהיה התאמת DNA תחת ההנחה שהנאשם אשם? התשובה לשאלה הזו היא כמובן 100%, כלומר 1.
כזכור, אנחנו מתעניינים בהסתברות כי הנאשם אשם בהינתן התאמת ה-DNA. כאן המקום לקרוא לדגל את נוסחת בייס:

ולאחר שעשינו את כל התרגיל הזה, כל מה שצריך זה להציב בנוסחה את ההסתברות שהנאשם אשם ואת ההסתברות המשלימה שהנאשם זכאי, ולהחליט האם התוצאה מעלה ספק סביר.
הנה הבעיה שלי: אם הנאשם אשם, ההסתברות שהוא אשם, לדעתי לפחות, שווה ל-1, ואז אם נציב את זה בנוסחה נקבל 1. ואם הנאשם זכאי, אז לדעתי ההסתברות שהוא אשם היא אפס, ואם נציב את זה בנוסחה נקבל אפס. זה לא ממש עוזר.
כאן יבוא הסטטיסטיקאי הבייסיאני ויאמר לכם כי ההסתברות שהנאשם אשם היא הסתברות סובייקטיבית, והיא למעשה ביטוי לרמת האמונה האפריורית שלנו כי הנאשם אשם (או זכאי). כאמור, אני לא מקבל את הטיעון הזה. לדעתי עלינו להניח כי הנאשם זכאי עד שתוכח אשמתו. במילים אחרות, אני אומר לסטטיסטיקאי הבייסיאני כי עליו להאמין מראש כי ההסתברות שהנאשם אשם היא אפס, ומכאן אני ממשיך את הטיעון ואומר כי כל התרגיל הזה חסר משמעות.
אבל יש מי שחושבים אחרת. יבוא מישהו ויגיד: "אני לא יודע אם הוא זכאי או אשם, ולכן אציב בנוסחה את הערך 0.5 להסתברות כי הנאשם אשם". החישוב ייתן לכן כי ההסתברות שהנאשם אשם בהינתן התאמת ה-DNA היא בערך 57.5%. אבל יכול לבוא מישהו אחר ולומר כי הנאשם ביצע בעברו שלושה מעשי אונס הדומים לאונס שבוצע בנרצחת סילבסטר, ולכן הוא מאמין כי ההסתברות שהנאשם אשם היא 0.75 (למה? ככה). עכשיו החישוב ייתן תוצאה של 80%. ספק סביר? אני לא יודע אבל מניח שכן. ברור שככל שנאמין יותר באשמת הנאשם, כך נקבל כי ההסתברות שהוא אשם בהינתן התאמת ה-DNA גבוהה יותר. במילים אחרות: אם מאמינים שהנאשם אשם מסיקים כי הוא אשם.
במקום אחר ברשת נתקלתי בטיעון בייסיאני אחר, שטוען כי יש לקחת בחשבון את ההסתברות כי הרוצח נמצא בכלל בתוך המאגר של 338000 הדגימות. אם ההסתברות כי הרוצח נמצא בתוך המאגר שווה לאפס, אז ברור כי הנאשם זכאי. אם ההסתברות הזו שווה ל-1, אז הנאשם אשם (בהנחה שאין עוד אדם במאגר שה-DNA שלו תואם לדגימה מזירת הרצח). מה קורה אם ההסתברות הזו נמצאת איפשהו בין אפס לאחד?
אם נסמן את ההסתברות הזאת ב-x, ונזכור כי ההסתברות שהנאשם אשם אם הרוצח לא נמצא במאגר היא בערך 0.27, נקבל בעזרת נוסחת בייס כי ההסתברות שהנאשם אשם היא:

ואנחנו שוב עומדים בפני השאלה: מהי ההסתברות כי הרוצח נמצא במאגר? במילים אחרות: מה ההסתברות כי הרוצח הוא מישהו שהורשע בעבירת מין נוספת/אחרת בקליפורניה ונלקחה ממנו דגימת DNA? עד כמה הידיעה כי ה-DNA של החשוד שנעצר זמן קצר לאחר הרצח ושוחרר לא נצא במאגר (כי הוא מת לפני שהחלו באיסוף דגימות DNA מעבריינים מורשעים) ((איש לא העלה בדעתו להוציא את הגופה מהקבר ולקחת ממנה דגימת DNA )) תשפיע על ההערכה שלכם ל-x?
כמו קודם – הניתוח הזה לא מוביל אותנו לשום מקום, כי אין לנו שום דרך אמינה לאמוד את x.
סיכום
זיהוי רוצחים או פושעים אחרים על ידי השוואת דגימות DNA שנלקחו מזירת הפשע למאגרי DNA הוא בעייתי, וטמן בחובו בעיות סטטיסטיות לא פשוטות, וזאת בנוסף לבעיות משפטיות ואחרות.
לקריאה נוספת
- Math on Trial: How Numbers Get Used and Abused in the Courtroom – Leila Schneps and Coralie Colmez
- Prosecutor’s fallacy — now with less fallaciousness! – QUOMODOCUMQUE blog
- DNA’s dirty little secret – Michael Bobelian – The Investigative Fund
- “Cold hit” DNA profiling – Possibly wrong blog
- Inside the mind of a juror: the problem with DNA – Laurie Meyers, Monitor Staff June 2007, Vol 38, No. 6
- DNA evidence is not foolproof – Alexandra Ossola, Popular Science, June 25, 2015
- Statisticians not wanted – Devlin's Angle blog
- The Dark Side of DNA Databases – Erin e. Murphy, The Atlantic, October 8, 2015
- If police find a DNA “match,” that doesn’t mean they have the right suspect – Jordan Ellenberg, Slate, June 5 2013
- It's a match! – Philip Dawid and Rachel Thomas, Plus Magazine, July 12, 2010
- How DNA evidence creates victims of chance – Linda Geddes, The New Scientist, 18 August 2010
נשלח: 6 במאי, 2018. נושאים: מה אומרת הסטטיסטיקה, על סדר היום.
תגובות: 5
| טראקבק
איך נדע האם המכוניות האוטונומיות בטיחותיות
התאונה הקטלנית של אובר
העולם גועש בימים האחרונים בעקבות תאונת הדרכים הקטלנית בה היה מעורב רכב אוטונומי של חברת אובר. התאונה הציתה ויכוחים שונים והעלתה נושאים ישנים לדיון מחודש. מתנהל למשל ויכוח בשאלה מי אשם בתאונה. התשובה, כמובן, תלויה במי שעונה לשאלה (אני לא מביע את דעתי בנושא הזה, ומבקש מכל מי שרוצה להביע את דעתו, שלא יעשה את זה בתגובות לפוסט הזה. זה לא המקום). הרשת התמלאה בשמועות על כך שנושא בטיחות המכוניות האוטונומיות אינו בעדיפות עליונה אצל חברת אובר. כמו כן ניצתו מחדש דיונים בתחום האתיקה שאמורה להדריך (אולי) את מתכנני המכוניות האוטונומיות. כך למשל, דפנה מאור, במאמר בעיתון דה-מרקר, שואלת שאלות חשובות במאמר עם הכותרת הפרובוקטיבית "האם תסכימו להידרס על ידי רובוט?" אמיתי זיו ענה לה שאם יידרס, אז הוא מעדיף להידרס על ידי מכונית אוטונומית (לא ברור לי למה זה משנה לו). אתם מוזמנים לקרוא את המאמרים האלה ומאמרים אחרים ולנהל דיונים ביניכם (אם כי, אני שוב מבקש להימנע מלנהל את הדיון הזה כאן בבלוג).
עוד כתבה מעניינת בדה-מרקר נשאה את הכותרת "אחת החולשות העיקריות של מכוניות אוטונומיות היא זיהוי הולכי רגל". הכותרת היא ציטוט של דברים שאמר אחד המרואיינים בכתבה, דני עצמון (שהינו בעל חברה המפתחת סימולטורים שנועדו לאמן ולשפר את היכולת של מערכות אוטונומיות ברכבים).
עצמון אמר דברים מעניינים נוספים. אני מצטט:
מכון ראנד האמריקאי ביצע בדיקה סטטיסטית שבאמצעותה קבע "רף נהיגה אנושי". "הם לקחו את על ההרוגים בתאונות בארה"ב ב-2015 וחילקו במספר המיילים שנסעו – וגילו שיש 1.1 הרוגים על כל 100 מיליון מיילים של נסיעה. זה הוגדר הרף האנושי – הביצועים של האדם די טובים… המכון חישב ומצא שכדי שמערכות אוטונומיות יגיעו לאותם ביצועים כמו של בני אדם בביטחון של 95%, עליהן לנסוע 11 מיליארד מייל. "בשנה שעברה כל החברות שעוסקות בתחום הזה בארה"ב נסעו ביחד בערך 4 מיליון מייל.
אז בואו נדבר על הסטטיסטיקה.
הסטטיסטיקה של תאונות הדרכים
אני חושב שכולכם תסכימו שככל שנוסעים יותר, יש יותר אינפורמציה על הסיכון לתאונות. אני למשל, לא הייתי מעורב באף תאונת דרכים עם נפגעים בשנתיים האחרונות. מצד שני, אני בקושי נוהג שתי נסיעות קצרות בעיר בכל שבוע ((פעם אחת לקניות, ופעם אחת כדי להסיע את הילד לחוג)) שמסתכמות אולי ב-15 קילומטר, שהם קצת פחות מ-800 קילומטר בשנה. ככל שנוסעים יותר, הסיכון להיות מעורב בתאונת דרכים גדל. נכון שהסיכון שונה מנהג לנהג, יש נהגים יותר זהירים ויש כאלה שפחות, אבל העיקרון ברור. לכן יש הגיון בחישוב של מכון ראנד שלוקח את מספר ההרוגים ביחס לכמות הנסועה. מייד אסביר את העקרונות של החישוב, ואציג כמה חישובים משל עצמי.
לפני שאתחיל בחישובים, אציג כמה נתונים שפירסמה הלשכה המרכזית לסטטיסטיקה. בשנת 2015 היו בישראל 12122 תאונות עם נפגעים, מתוכן 292 תאונות קטלניות, 1558 תאונות עם פצועים קשה, ו-10272 תאונות עם נפגעים בדרגת פציעה בינונית או קלה. בתאונות האלה נהרגו 322 איש, 1796 איש נפצעו קשה, ו-20046 איש נפצעו בינוני או קל. ומכאן שהיו תאונות קטלניות בהן היה יותר מהרוג אחד, והוא הדין לגבי הנפגעים האחרים. לכן אתייחס בהמשך למספר התאונות ולא למספר הנפגעים.
האם המספרים האלה גבוהים או נמוכים? תלוי איך מסתכלים על הנתונים. אל תטעו. לדעתי כל תאונה היא טרגדיה. עם זאת, לפעמים צריך להסתכל על המספרים עצמם, וזאת כדי שיהיה אפשר לקבל החלטות מושכלות. כמו שדני עצמון הסביר, צריך להסתכל גם על הנסועה – שהיא סך כל הנסיעות שנסעו כלי הרכב במדינה. ((לדוגמא, אם 10 מכוניות נסעו מתל אביב לחיפה, מרחק של 100 ק"מ, אז הנסועה הכוללת שלהן הייתה 10×100 כלומר 1000 ק"מ)). לפי נתוני הלשכה המרכזית לסטטיסטיקה, הנסועה בישראל בשנת 2015 הייתה 54,820 מיליון ק"מ, כלומר כמעט 55 מיליארד ק"מ. מכאן אפשר לחשב כי על כל מיליון ק"מ של נסועה היו בשנת 2015 היו בישראל 0.00533 תאונות קטלניות. זה נראה כמו מספר יותר קטן, אבל זה רק עניין של קנה מידה. באותו אופן ניתן לחשב כי בישראל היו 0.02842 תאונות דרכים עם פצועים קשה (אך ללא הרוגים) לכל מיליון ק"מ, ו-0.18737 תאונות שבהן היו פצועים בינוני או קל (אך לא פצועים קשה ולא הרוגים). בסך הכל היו בישראל 0.22295 תאונות עם נפגעים לכל מיליון ק"מ של נסועה.
הסטטיסטיקאים מכנים את המספרים המתארים את מספר התאונות למיליון ק"מ בשם "קצב התאונות" (או rate באנגלית). זה מדד כללי המתאר את מספר האירועים ליחידת מדידה (בדרך כלל זמן, אך כפי שראיתם, יש גם יחידות מדידה אחרות). דוגמא נוספת ((תסלחו על על הדוגמאות המדכאות)) לנתונים כאלה יכולה להיות המספר הממוצע של גידולים ממאירים חדשים המתגלים במשך חודש. לפני נתוני הלמ"ס, בשנת 2013 היו בישראל בסך הכל 13546 גברים אצלם התגלו גידולים ממאירים חדשים. זה אומר שקצב הופעת הגידולים החדשים היה בקירוב 1128.8 בחודש.
איך להעריך את רמת הבטיחות של המכוניות האוטונומיות?
עכשיו, כאשר הבנו את הנתונים האלה ומשמעותם, אנחנו יודעים איך להעריך את הבטיחות של המכוניות האוטונומיות. צריך לחשב מהו קצב התאונות שלהן, ולהשוות אותו לקצב של המכוניות ה-"רגילות".
כאן אנחנו נתקלים בבעיה הראשונה: אין נתונים. אנחנו יודעים כי הנסועה הנוכחית של המכוניות האוטונומיות היא בערך 4 מיליון מייל, אבל לא יודעים כמה תאונות היו. לכן אנחנו גם לא יודעים האם מספר ההרוגים עד כה (1) הוא גבוה או לא. מה שאנחנו כן יכולים להגיד במידה רבה של בטחון הוא שגודל המדגם קטן מדי. לפי גודל המדגם הנוכחי האומדן שלנו לקצב התאונות הקטלניות של המכוניות האוטונומיות הוא 0.15385 למיליון ק"מ, כמעט פי 29 מהנתון המקביל של ישראל בשנת 2015. עם זאת, יש לסייג את הדברים ולומר כי האומדן הזה מאוד לא מדוייק, שוב, בגלל גודל המדגם הקטן. רווח הסמך לקצב, ברמת סמך של 95%, הוא 0.0053 עד 0.5535. זה אומר שייתכן מאוד שקצב התאונות הקטלניות של המכוניות האוטונומיות דומה לקצב של ישראל. שוב, ככל שיצטברו יותר נתונים, האומדן יהיה מדוייק יותר, ובהחלט יכול להיות שב-4 מיליון המייל הבאים לא תהיה אף תאונה קטלנית, ואז אומדן הקצב יקטן ב-50%.
רבים טוענים כי המכוניות האוטונומיות הינן בטוחות יותר ממכוניות רגילות, ואני נוטה להסכים איתם באופן חלקי (אם כי, כמו תמיד, אלוהים מצוי בפרטים הקטנים – ראו שוב את מאמרה של דפנה מאור). אך טענות צריך לגבות בנתונים, וכאמור, אין לנו מספיק נתונים. לכן השאלה שצריך לשאול היא: כמה נתונים צריך כדי שנוכל לומר משהו אינטליגנטי ומגובה בנתונים על הבטיחות של המכוניות האוטונומיות?
כפי שכבר הבנתם, הסטטיסטיקאים של מכון ראנד כבר ערכו חישוב כזה. אני מודה שאני לא כל כך מבין את הנתון של 11 מיליארד מייל שדני עצמון ציטט, ואני מניח שחלק מהדברים "אבדו בתרגום". בכל מקרה, אני מתכוון להציג כאן את העיקרון שלפיו עורכים את החישובים, ולהציג את התוצאות של החישובים שלי.
מודל להתרחשות תאונות דרכים
קוראיי הוותיקים כבר יודעים: כדי לבצע את החישובים הסטטיסטיים יש צורך במודל הסתברותי. להזכירכם, מודל הוא תיאור של המציאות, שייתכן שאינו מדוייק לגמרי, אבל הוא מספיק טוב כדי לתת תשובה אמינה לשאלה שלנו. כל מודל מתבסס על הנחות. הנחות שונות יובילו למודלים שונים ולתשובות שונות.
המודל שאציג לקצב תאונות הדרכים מתבסס על הנחה יחידה: הפיזור של התאונות לאורך השנה הוא אחיד. במילים אחרות, אין תקופות בשנה שיותר מועדות לתאונות מאשר תקופות אחרות. אפשר כמובן להניח הנחות אחרות, שיגדירו מודלים יותר מסובכים. אני אגביל את עצמי למודל הפשוט, כיוון שהמטרה העיקרית שלי היא להסביר את העקרונות הסטטיסטיים. עם זאת, אני לא חושב שמודל מסובך יותר ייתן תוצאות שונות באופן משמעותי, וזאת לאור הניסיון שצברתי במשך השנים בניתוח נתונים דומים.
מההנחה שלי אפשר, עם קצת מתמטיקה, להסיק כי מספר התאונות בשנה הוא משתנה מקרי פואסוני. שוב קוראיי הוותיקים אולי זוכרים שהמודל הזה וההתפלגות הנובעת ממנו הוזכרו כבר בבלוג. זה המודל בו השתמשו הבריטים כדי לבדוק מה הייתה רמת הדיוק של הטילים שהמטירו עליהם הגרמנים בזמן הבליץ על לונדון. למשתנה מקרי שהתפלגותו היא התפלגות פואסון יש פרמטר אחד בלבד – פרמטר הקצב. בישראל של 2015 קצב התאונות הקטלניות היה כזכור 0.00533 למיליון קילומטר. השאלה המעניינת היא: כמה מיליוני ק"מ צריכות המכוניות האוטונומיות לנסוע כדי לנוכל לומר על סמך הנתונים כי קצב התאונות שלהם נמוך מקצב התאונות הקטלניות של ישראל באופן משמעותי? עם קצת מתמטיקה לא מסובכת במיוחד אפשר לפתח נוסחה שנותנת את התשובה. הנה היא, לא להיבהל, תיכף אסביר הכל, ומי שלא מעוניין בהסברים יכול לדלג הלאה, אל המספרים שחישבתי.

ההסברים: למבדה-אפס (האות שדומה לאות העברית גימל) מייצגת את קצב הבסיס שאליו אנחנו רוצים להשוות את הקצב מהמדגם. בדוגמא שלנו קצב הבסיס הוא הקצב של תאונות הדרכים הקטלניות בישראל, כלומר 0.00533 תאונות למיליון קילומטר. האות דלתא (שדומה לאות למד בעברית) מייצגת את ההבדל המשמעותי בין קצב התאונות במדגם (כלומר קצב התאונות של המכוניות האוטונומיות) ובין קצב הבסיס. לדוגמא, אם אנחנו חושבים שהבדל משמעותי יהיה ירידה של 10% בקצב התאונות, הרי שאנו מצפים שקצב התאונות של המכוניות האוטונומיות יהיה 0.004797 (90% מ-0.00533), ולכן ההפרש דלתא שווה ל–.000533. שימו לב שההפרש הוא שלילי. אלפא וביתא הן רמת המובהקות והעוצמה, אני אשתמש בערכים של 5% -90% בהתאמה, והאות Z מסמלת ערכים של ההתפלגות הנורמלית, והם שווים ל-1.645 עבור רמת המובהקות ו- -1.282עבור העוצמה. התוצאה שמתקבלת על ידי החישוב, n, היא גודל המדגם הדרוש, שהוא במקרה שלנו, מספר מיליוני הקילומטרים שהמכוניות האוטונומיות צריכות לנסוע.
מה גודל המדגם הדרוש להערכת הבטיחות?
אם נציב את כל המספרים בנוסחה נקבל כי כדי שנוכל לזהות ירידה מובהקת של 10% בקצב התאונות הקטלניות, נצטרך לראות מה קורה אחרי שהמכוניות האוטונומיות ייסעו 9215 מיליון ק"מ, שהם בערך 6 מיליארד מייל. זה אמנם מספר קטן יותר מהמספר שצוטט בכתבה ((אני לא יודע מה היו ההנחות שלהם ומה הם חישבו בדיוק)), אבל זה עדיין מספר מטורף. (אני נותן כאן קישור לקובץ אקסל שבעזרתו ביצעתי את החישובים. אתם מוזמנים לבדוק עוד תרחישים).
אחת הסיבות שקיבלנו מספר כל כך מטורף היא שהגדרנו ירידה מאוד קטנה כמשמעותית – רק 10%. יש הטוענים כי כשהמכוניות האוטונומיות ייכנסו לשימוש מסחרי קצב התאונות (או מספר התאונות, שזה בעצם אותו דבר), ירד בצורה הרבה יותר משמעותית. אם זה נכון, גודל המדגם יהיה הרבה יותר קטן. על פי אותה הנוסחה, כדי לזהות באופן מובהק ירידה של 50% בקצב תאונות הדרכים הקטלניות, יש צורך בגודל מדגם של כ-471 מיליון מייל, וכדי לזהות ירידה משמעותית של 90% במספר תאונות הדרכים הקטלניות באופן מובהק יש צורך בגודל מדגם של קצת פחות מ-220 מיליון מייל.
החדשות הטובות הן שכדי לזהות ירידה מובהקת של 90% בקצב הכולל של תאונות דרכים עם נפגעים יש צורך בגודל מדגם של קצת יותר מ-5 מיליון מייל, ואנחנו כמעט שם. מצד שני, יש המון חברות שעורכות המון ניסויים, ולא סביר שיוקם מאגר נתונים בו יקובצו הנתונים של כל החברות, שהרי כל חברה רוצה לשמור את הנתונים שלה בסוד מהמתחרות. אז אנחנו לא באמת מתקרבים ליעד של 5 מיליון מייל.
עוד חדשות טובות: הנסועה השנתית בארצות הברית היא קצת יותר מ-3 טריליון מייל, כלומר 3000 מיליארד מייל (או 3 מיליון מיליוני מייל), כך שאם באורח פלא כל המכוניות בארצות הברית יהפכו להיות אוטונומיות, נדע את כל התשובות תוך יום בערך. זה לא יקרה כמובן. אפשר להמשיך ללהטט בחישובים שייקחו בחשבון את קצב חדירת המכוניות האוטונומיות לשימוש, אבל אני אעצור כאן.
מתי נדע האם המכוניות האוטונומיות בטיחותיות?
המסקנה שלי היא שייתכן שנדע יחסית בקרוב (אם תהיה התערבות רגולטורית) האם המעבר למכוניות אוטונומיות יביא לירידה מאוד גדולה (90%) במספר תאונות הדרכים עם נפגעים. אם הירידה קטנה יותר, נצטרך לחכות זמן רב יותר. בקשר לתאונות דרכים יותר חמורות, כאלה עם פצועים קשה או תאונות קטלניות, יעבור עוד המון זמן עד שנדע משהו. מה שיקרה בפועל הוא שמכוניות אוטונומיות ייכנסו לשימוש בלי שיהיה לנו מושג ירוק על רמת הבטיחות שלהן.
נשלח: 23 במרץ, 2018. נושאים: מה אומרת הסטטיסטיקה, ניהול סיכונים, על סדר היום.
תגובות: 4
| טראקבק
הערות על חישוב מדד השכירות של הלשכה המרכזית לסטטיסטיקה
ביום שני השבוע, 29.1.208, התפרסמה בגלובס כתבה שדיווחה על טעות מהותית בחישוב מדד השכירות של הלשכה המרכזית לסטטיסטיקה, עליה דיווחה המייעצת שהקימה הממשלה לבחינת מדדי המחירים בשוק הנדל"ן.
הפעם אתחיל מהסיכום
- הועדה התייחסה בצורה עניינית לנושא אמידת שכר הדירה. אין המלצה לתקן את המדדים לאחור, ואין המלצה לשנות את מתודולוגיית הדגימה.
- בניגוד למה שנאמר בכתבה, הועדה לא מתחה ביקורת על המתודולוגיה של הלמ"ס, אלא המליצה על שיפור בעניין ממוקד יחיד במתודולוגיה.
- הפער שדווח בכתבה אינו בין נתוני הועדה ונתוני הלמ"ס, אלא בין נתוני הלמ"ס ונתונים של ד"ר רז-דרור, שאיני מזלזל בכישוריו.עם זאת, לא ברור מהי המתודולוגיה בה ד"ר רז-דרור השתמש כדי לאמוד את גובה שכר הדירה. כמו כן, נתוניו ככל הנראה פחות מדוייקים עקב מדגם קטן יחסית.
- הפער בין הנתונים של הלמ"ס והנתונים של ד"ר רז-דרור נמוך ממה שדווח בכתבה. הפער שעלול לנבוע בין ערכו של מדד המחירים לצרכן כפי שדווח ובין ערכו התיאורטי, בהנחה שהנתונים של רז-דרור נכונים ומדוייקים, הוא זניח ולא מדווח בכתבה.
- הקביעה של דרור מרמור כי הטעות של הלמ"ס היא "חלמאית" הינה לחלוטין חסרת בסיס. הפרשנות של מעמירם ברקת על "תיבת הפנדורה" שתיפתח מבוססת על המידע המטעה בכתבה של דרור מרמור, ויש להתייחס אליה בהתאם. ההתנפלות של סטלה קורין-ליבר על המועצה הציבורית לסטטיסטיקה (שאני מכיר אישית את רוב החברים בה) מתבססת אף היא על הקביעות הלא מדוייקות של מרמור, ואינה מביאה שום טענה עניינית. איתן כבל מיהר לגזור קופון פוליטי (לפחות הוא סייג את דבריו והתנה אותם בכך שמרמור צודק בדברים שכתב – הוא לא).
מה בדיוק קרה?
הנה ציטוטים מהכתבה:
"מדד שכר הדירה של הלמ"ס, המהווה 5.7% ממדד המחירים לצרכן (האינפלציה), כלל במשך השנים טעות מובנית וכמעט חלמאית, שהטתה בפועל את המחירים בשוק השכירות באחוזים ניכרים כלפי מטה. תיקון הטעות לאחור יעלה בדיעבד גם את מדד המחירים לצרכן, וישנה את חישובי האינפלציה בשנים האחרונות… מאז 2008 נוצר פער של כ-25% בין שני סוגי המדידה. לפי החישובים החדשים, מאז 2008 עלה מדד שכר הדירה בכ-65%, לעומת עלייה כוללת של 40% לפי מדד שכר הדירה הישן, תוספת שמגלמת יותר מאחוז אינפלציה בעשור האחרון"
הכתבה ממשיכה:
"לכל מי שמכיר את שוק הדיור ברור כי דווקא חילופי שוכרים מהווים לא פעם הזדמנות להקפצת המחירים – ללא שום ביטוי לכך במדד. לפי הדוח, בדיקה שנערכה בעבר בלמ"ס העלתה ששוכרים שהחליפו דירות שילמו בממוצע 6.6% יותר משוכרים שנשארו בדירותיהם"
הכתב דרור מרמור מביא ציטוטים מדו"ח הועדה המייעצת:
"בשוק המצוי במגמה של עליית מחירים, צפויה הטיה כלפי מטה במדד שכר הדירה, הואיל וחלק מהדיירים עוברים לדירה אחרת בשל דרישה לדמי שכירות גבוהים יותר. ..לחילופין, בשוק המצוי במגמת ירידת מחירים, ההטיה עשויה להתרחש כלפי מעלה, שכן המשכיר עשוי להוריד את שכר הדירה בעת התחלפות דיירים כדי להימנע ממצב שבו הדירה נותרת ריקה"
עוד ממשיך הכתב ומסביר:
"מאז 1999 מדד מחירי הדירות (מכירה) אינו חלק ממדד המחירים לצרכן, ובמקומו מחושב השינוי במחירי שכר הדירה. בלמ"ס מדגישים כי ההטיה המוטעית לא השפיעה על כל מרכיב הדיור בשכירות, התופס נתח משמעותי של כ-24% בתוך מדד המחירים לצרכן, אלא רק על אותם 5% מהמדד שבוצעו באמצעות החישוב המוטה (החישוב המשלים מתבסס על מחירים ממוצעים)"
לכתבה עצמה נלוו גם טורי פרשנות ותגובות שעסקו באפוקליפסה של טעות החישוב שדווחה. עמירם ברקת כותב על העדכון שפותח תיבת פנדורה. סטלה קורין ליבר כותבת על המחדל של מדד הלמ"ס: בכירים שבבכירים לא עשו את עבודתם. ח"כ איתן כבל הכריז כי לחשיפה על טעות הלמ"ס יש השפעה דרמטית, וקרא לכנס את כל גורמי המקצוע בתחום הדיור כדי להבין את חישוב הנתונים השגוי של הלמ"ס.
בכתבה של גלובס הובאה תגובתו של דורון סייג, מרכז הוועדה מטעם הלמ"ס:
"הלמ"ס החלה בבדיקות לאמידה מדויקת וטובה יותר של ההטיה. לדברי סייג, "הפער שנמצא על ידי רז דרור, בשיעור של 25%, לא חושב על ידי הלמ"ס ואנחנו מבצעים כעת בדיקה טובה יותר. כרגע מדובר בבדיקה ראשונית, אבל לנו נראה שהפער שיימצא בסוף בין המדד שהוצג למדד החדש יהיה נמוך יותר".
ב-Ynet, מובאת תגובה נרחבת יותר מטעם הלמ"ס ((לא מצאתי בגלובס)):
"(אנשי המקצוע) מודעים לאי הדיוק בחישוב של מדד שכר הדירה הנכלל במדד המחירים לצרכן, והסבירו זאת בקשיי איסוף נתונים אודות שוכרים חדשים, אך עם זאת טענו כי מדובר בהשפעה מינורית: מבדיקות שונות שביצענו עולה שהשפעת שכר הדירה של שוכרים חדשים על מדד המחירים לצרכן זניחה. מסקנה זאת מוסברת בין השאר בכך שמדובר על 5.7% ממדד המחירים לצרכן וקבוצת השוכרים החדשים מהווה על סמך בדיקות ראשוניות שערכנו לא יותר מאשר 20% מתוך אוכלוסיית השוכרים"
כמו כן הסבירו כי בניגוד לנטען בפרסומים השונים, הודיעו על בדיקת הנתונים לאחור ולא על תיקונם לאחור.
עם זאת, בלמ"ס לא פסלו כי יוחלט לתקן את המדד בהמשך ואמרו: "עם סיום תוצאות הבדיקות וטיוב הנתונים לגבי שוכרים חדשים, ובהתייעצות עם הוועדה הציבורית המייעצת בנושאי בינוי, דיור ונדל"ן נחליט על המשך הטיפול".
Ynet מיידעים את קוראיהם גם על תגובת בנק ישראל, שם טוענים כי ההשפעה אינה משמעותית:
"בנק ישראל עומד בקשר רציף עם גורמי המקצוע בלמ"ס. בדיקות ראשוניות שנערכו בבנק ישראל מראות שהשפעת ההבדל במדידה על האינפלציה במדד המחירים לצרכן קטנה, ובוודאי שלא הייתה מביאה לשינוי במדיניות המוניטרית".
בואו נעשה סדר במספרים
בואו נדבר על הפער בין שתי ההערכות. לפי הלמ"ס, שכר הדירה עלה בין 2008 ל-2015 ב-40%, ולפי חישובי הועדה המייעצת שהם לצעשה חישוביו של ד"ר רז-דרור, העלייה הייתה בגובה 65%.
במילים אחרות, אם שכר הדירה לדירה ממוצעת ב-2008 היה 1000 ₪, הרי שלפי הלמ"ס שכר הדירה ב-2015 היה 1400 ₪ ולפי הועדה הוא היה 1650 ₪. מה הפער? ההפרש בין 1650 ב-1400 הוא 250. נחלק את ההפרש הזה ב-1400 ונכפיל ב-100 ((חישובי אחוזים של בי"ס יסודי)) ונקבל כי התוצאה היא קצת פחות מ-18%, ולא 25%. הפער פחות גדול ממה שנאמר בכתבה,
נמשיך. מדובר בפער הכולל שנפתח לאורך 8 שנים. מהו הפער הממוצע בשנה? זה חישוב קצת יותר טריקי: הפער הממוצע הוא השורש השמיני של 1.18. החישוב מראה כי הפער הממוצע בשנה הוא קצת פחות מ-1.8% בשנה ((ידע בחישובי אחוזים של בית ספר יאפשר לכם לבדוק את התוצאה. תתחילו מ-100, תוסיפו לו 1.8%. לתוצאה שקיבלתם תוסיפו שוב 1.8%, וכך הלאה, 8 פעמים)). כמו כן, חישוב דומה יראה כי לפי אומדני הועדה, העלייה הממוצעת בשכר הדירה לאורך 8 השנים האלה הוא כ-6.5%, ופי הלמ"ס העלייה הממוצעת בשנה היא כ-4.3%.
מה ההשפעה של זה על המדד? לפי מחשבון מדד המחירים של הלמ"ס, מ-2008 עד 2015 עלה מדד המחירים לצרכן בקצת יותר מ-16%. זו עליה ממוצעת של 1.7% בשנה כלומר, אם מחיר סל המצרכים שלפיהם מחושב המדד היה 1000 ₪ בתחילת שנה ממוצעת, מחירו בסוף השנה היה 1017 ₪.
שכר הדירה מהווה 5.7% מסל המצרכים ((לפי הנתון בכתבה בגלובס)). נעגל את זה ל-6%. פירוש הדבר הוא שאם ערך סל המצרכים היה בתחילת השנה 1000 ₪, שכר הדירה היה 60 ₪, וערכו של שאר הסל היה 940 ₪.
לפי הלמ"ס, שכר הדירה עלה במשך השנה בכ-3.8%, ולכן בסוף השנה הוא היה כ-62 ₪. מכאן שערכו של שאר הסל בסוף השנה היה 955 ₪.
לפי הועדה המייעצת, שכר הדירה בשנה ממוצעת עלה ב-6.5%. נעגל את זה ל-7%. כלומר אם עלות הסל בתחילת השנה הייתה 1000 ₪, הרי ששכר הדירה היה, כפי שחישבנו, שכר הדירה בתחילת השנה היה, כפי שחישבנו, 60 ₪. אם הוא עלה ב-7% במשך השנה, הרי שבסופה הוא היה כ-64 ₪. שווי שאר המצרכים בסוף השנה היה 955 ₪, ולכן השווי הכולל של הסל היה 1019 ₪. אם הועדה צודקת, האינפלציה השנתית הממוצעת הייתה 1.9%, ולא 1.7%.
אני לא כלכלן, ולכן לא יודע עד כמה ההבדל הזה משמעותי. התחושה שלי היא שלא מדובר בקטסטרופה.
איך אומדים את העלייה בשכר הדירה?
אקדים ואומר כי אני לא מתמחה בדגימה. הידע שלי בתחום מוגבל למה שלמדתי בלימודי התואר הראשון, פלוס קצת ידע נוסף שרכשתי בעזרת לימוד עצמי.
אבל הנה תיאור בסיסי של התהליך. כדי לדגום, צריך להגדיר קודם כל את מסגרת הדגימה, שהיא בעצם האוכלוסייה שבה אנו מתעניינים. במקרה שלנו, אנחנו רוצים לאמוד את שכר הדירה הממוצע, ולכן יש לנו שתי מסגרות דגימה אפשריות.
אפשרות אחת היא לערוך רשימה של כל הדירות המושכרות, ואז ניקח מדגם של דירות מושכרות ונברר מה שכר הדירה עבור כל דירה שנכללת במדגם.
אפשרות שניה היא לערוך רשימה של כל משקי הבית ששוכרים דירות, לקחת מדגם מתוך משקי הבית האלה, ולברר מה שכר הדירה שהם משלמים.
יש שתי דרכים עיקריות לביצוע המדגמים. ניתן לבצע מדגם בחתך רוחבי (cross sectional), כלומר לקחת כל חודש מדגם חדש, או באופן אורכי (longitudinal), כלומר לקחת מדגם ולעקוב אחריו לאורך זמן.
לכל שיטה יש יתרונות וחסרונות, שלא אפרט כאן ((בין היתר, כיוון שאני לא מומחה בתחום)).
אני מציע שכעת תפסיקו את הקריאה לדקה או שתיים, ותחשבו מה אתם הייתם עושים אם הייתם מתבקשים לבצע את המדגם: האם הייתם דוגמים דירות או שוכרים? האם הייתם לוקחים כל חודש מדגם חדש, או שהייתם לוקחים מדגם ועוקבים אחריו לאורך זמן? אולי תחשבו על דרך אחרת?
מסתבר שהדברים לא כל כך פשוטים. קשה מאוד, אולי בלתי אפשרי, לערוך רשימה של כל הדירות המושכרות. קשה מאוד, אולי בלתי אפשרי, לערוך רשימה של כל משקי הבית המתגוררים בדירות שכורות. בלמ"ס בחרו בדרך ביניים. למעוניינים, הנה לינק למסמך המתאר את מתודולוגיית חישוב סעיף הדיור במדד המחירים לצרכן (קישור לקובץ pdf). אפשר להתווכח על מתודולוגיית הדגימה, אך רצוי מאוד להבין את הנושא לפני שמחווים דיעה.
מה אומר דו"ח הועדה המייעצת?
אמנם בגלובס לא טרחו לתת הפניה אל הדו"ח אבל חיפוש מהיר בגוגל מצא אותו (קישור לקובץ pdf).
כדאי קודם כל לעיין בעמוד 2 בו תמצאו את רשימת חברי הועדה. בוועדה יש 35 חברים, שהם נציגים ממגוון רחב של מוסדות ממשלתיים ואחרים, כולל בנק ישראל, משרד האוצר, משרד הבינוי והשיכון, המועצה הלאומית לכלכלה, משרד המשפטים, וכן, גם 9 נציגים של הלשכה המרכזית לסטטיסטיקה. גילוי נאות: אני מכיר אישית שלושה חברים בוועדה.
ההתייחסות של הועדה לנושא מדד שכר הדירה נמצאת בעמודים 37-39. הנתון של עליית המחירים ב-65% אינו כתוב במפורש בדו"ח והוא ככל הנראה נגזר מהגרף שבעמוד 37. לדעתי הגרף מראה שינוי הקרוב יותר ל-60% מאשר ל-65%, (ראו הצגה מוגדלת של הגרף בדה-מרקר) אבל בואו נניח לזה. בעיה יותר גדולה בגרף, לדעתי, היא שהוא לא מציג סטייות תקן או רווחי סמך לאומדנים, לא עבור הנתונים של רז-דרור ולא עבור נתוני הלמ"ס. ((אכתוב על עניין זה בהרחבה בקרוב))
בשולי הגרף מצויין כי מקור הגרף במסמך של ד"ר עופר רז-דרור מ-2017. לא הצלחתי לאתר את המסמך המקורי. בדה-מרקר מציינים כי המדגם של רז-דרור קטן יחסית, מה שאומר כי סטיית התקן שלו (טעות הדגימה) יותר גדולה. לא הצלחתי למצוא מה הייתה שיטת הדגימה של ד"ר רז-דרור.
המלצות הועדה בנושא הן לשפר את המעקב אחר דירות בשכירות בעת תחלופת שוכר, וכן לפרסם מדדים לשכר-דירה ואת שכר הדירה הממוצע בפילוח לפי מחוזות וערים גדולות. בניגוד למה שדווח בגלובס, אין המלצה לתקן את המדדים לאחור, ואין המלצה לשנות את מתודולוגיית הדגימה.
משפט מסכם אחרון: תמיד כדאי לקרוא בביקורתיות כתבות, דו"חות, כל דבר בעצם. תהיו ספקנים.
נשלח: 2 בפברואר, 2018. נושאים: כלכלה וחברה, מה אומרת הסטטיסטיקה, על סדר היום.
תגובות: 2
| טראקבק